HyperLogLog版 COUNT(distinct)
背景
ユニークユーザ数やユニークアイテム数(これをカーディナリティと呼びます)の集計を目的として、しばしば大量のデータセットに対してSELECT COUNT(distinct KEY)構文を実行する事があります。
しかし、キー値の重複排除とGPUを含む並列・分散処理との間には厄介なジレンマが存在します。
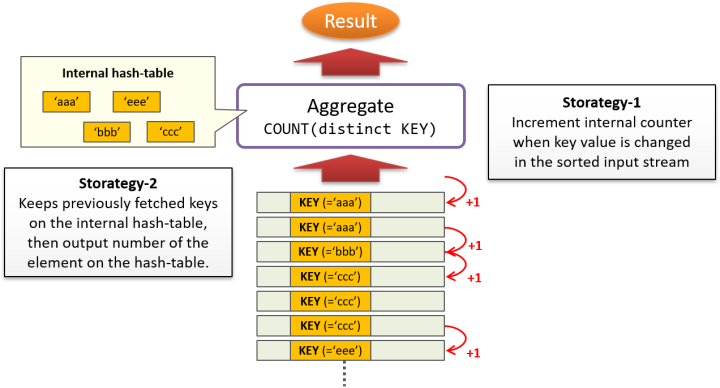
キー値の重複排除を実装する場合、2つの戦略を考える事ができます。
一つは、集計処理を行う Aggregate 処理への入力を予めキー値でソートしておき、キー値の値が変化するたびにカウンタをインクリメントするという実装。単純ですが、大量のデータをソートするのは重い処理である上に、レコードを処理する順序に強く依存する方式であるため、シングルスレッドで実行するほかありません。
もう一つは、集計処理を行う Aggregate 処理ノードの内部にハッシュ表を作成し、重複排除のためにキー値を全てトラックするという方法が考えられます。メモリ消費量が事前に予測し難く、過大なリソースを消費してしまう事があります。
これらの特性が、集約関数COUNT(distinct KEY)をGPUで並列実行する上での障害となっており、現在のところ、PG-Stromではこれをサポートしていません。
概要
例えばCOUNT(distinct KEY)で集計したユニークユーザ数を単にグラフとして出力する、つまりある程度の誤差は十分に許容範囲であるような利用シーンにおいては、厳密にキー値の重複排除と集計を行うのではなく、代わりに、ある程度の正確さが数学的に予測された推定値で代替するという方法が考えられます。
HyperLogLogとは、大きなデータセットから重複しないキー値の数を推定するためのアルゴリズムです。その特性から、大規模なテーブルのスキャンを複数のプロセスで分割統治する事が容易で、消費するメモリサイズは十分に小さく事前に予測可能であるといった、GPUでの処理に適した特性を備えています。
基本的な考え方を説明します。
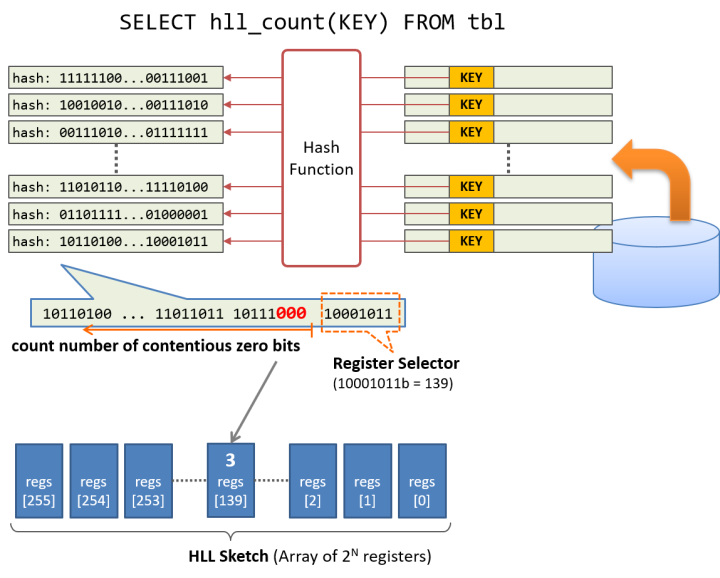
はじめに、重複排除を行うキー値をハッシュ関数にかけ、ハッシュ値を計算します。ハッシュ関数の性能が十分に良ければ、キー値に対応するハッシュ値のビットパターンはランダムに分布すると仮定します。そうすると、何種類ものキー値から導出したハッシュ値の中には、0が連続して出現するような特徴的なものも存在すると考えられます。
例えば、32種類のキー値が存在するデータセットであれば、キー値から生成したハッシュ値の中に、.... 10110000 というように、下位ビットから4個の0が連続するというパターンが出現する事は不思議ではないでしょう。このようにHyperLogLogでは、生成したハッシュ値のビットパターンのうち、下位ビットから連続した0の個数の最大値を調べる事で、元のデータセットのカーディナリティを推定するのです。
実用上は、ハッシュ値のうち何ビットかを「レジスタセレクタ」として使用します。例えば8bit分をセレクタとして使用するのであれば、256個のレジスタからなるHLL Sketchを予め確保し、ハッシュ値の下位8bitを用いてHLL Sketch上のレジスタを指定します。そして、残るハッシュ値のうち最下位ビットからの連続する 0 の個数をカウントして、レジスタ毎にその最大値を記録します。 最後にスキャンの終了後、256個のレジスタの内容を平均(調和平均)し、補正を加える事で、比較的精度の高いカーディナリティの推定を行う事ができます。
レジスタに記録するのは下位ビットから連続する0の個数です。したがって、PG-Stromで利用する64bitのハッシュ関数なら、それぞれ8bitもあれば十分に必要な情報を記録する事ができ、レジスタの数が256個であれば必要な記憶領域の合計は僅かに256バイトにすぎません。
利用方法
count(distinct KEY)の代わりに、PG-Stromが独自に提供する集約関数hll_count(KEY)を使用する事で、HyperLogLogを使用したカーディナリティの推測を行う事ができます。
例えば、以下のクエリで厳密に重複排除を行ったlo_custkey列のカーディナリティ数は2,000,000ですが、6億行(87GB)のテーブルlineorderからこれを導出するのに400秒以上を要しています。
実行計画を見ると、CPU並列クエリは選択されておらず、シングルプロセスでテーブル全体をスキャンしている事が分かります。
=# select count(distinct lo_custkey) from lineorder ;
count
---------
2000000
(1 row)
Time: 403360.908 ms (06:43.361)
=# explain select count(distinct lo_custkey) from lineorder ;
QUERY PLAN
------------------------------------------------------------------------------
Aggregate (cost=18896094.80..18896094.81 rows=1 width=8)
-> Seq Scan on lineorder (cost=0.00..17396057.84 rows=600014784 width=6)
(2 rows)
一方、count(distinct lo_custkey)の代わりにhll_count(lo_custkey)を利用すると、カーディナリティの推測値2,005,437(実際の値に対する誤差率0.3%)という比較的正確な値を、同じハードウェア上で40倍以上も高速に導出できている事が分かります。
実行計画を確認すると、CPU並列クエリに加えて、GPUでの集約、GPU-Direct SQLといった各種の高速化技術を利用している事が分かります。
=# select hll_count(lo_custkey) from lineorder ;
hll_count
-----------
2005437
(1 row)
Time: 9660.810 ms (00:09.661)
=# explain select hll_count(lo_custkey) from lineorder ;
QUERY PLAN
----------------------------------------------------------------------------------------------------------
Aggregate (cost=4992387.95..4992387.96 rows=1 width=8)
-> Gather (cost=4992387.72..4992387.93 rows=2 width=32)
Workers Planned: 2
-> Parallel Custom Scan (GpuPreAgg) on lineorder (cost=4991387.72..4991387.73 rows=1 width=32)
Reduction: NoGroup
Outer Scan: lineorder (cost=2833.33..4913260.79 rows=250006160 width=6)
GPU Preference: GPU0 (Tesla V100-PCIE-16GB)
GPUDirect SQL: enabled
(8 rows)
注意事項
HyperLogLogのアルゴリズムの特性上、キー値のカーディナリティが小さい属性に対しては推定誤差が無視できないほど大きくなります。
例えば、以下のlineorderテーブルのlo_orderpriority列は、'1-URGENT'から'5-LOW'まで僅か5種類の値しか持ちえません。
count(distinct lo_orderpriority)により、厳密な重複排除を行って集計すると結果は5と出力されます。
一方、hll_count(lo_orderpriority)を用いてカーディナリティの推測を行った場合、その結果は370と出力されてしまいました。
hll_count()の利用に際しては、データの特性や分布に対しても注意が必要です。
=# select count(distinct lo_orderpriority) from lineorder ;
count
-------
5
(1 row)
=# select hll_count(lo_orderpriority) from lineorder ;
hll_count
-----------
370
(1 row)
HLL Sketchの再利用
もう一度、集約関数 hll_count() を実行した時の実行計画を確認してみます。
explain verboseを実行すると、それぞれの処理ステップでどのような出力が行われるのかを確認する事ができます。
=# explain verbose select hll_count(lo_custkey) from lineorder ;
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------
Aggregate (cost=4992387.95..4992387.96 rows=1 width=8)
Output: hll_merge((pgstrom.hll_sketch_new(pgstrom.hll_hash(lo_custkey))))
-> Gather (cost=4992387.72..4992387.93 rows=2 width=32)
Output: (pgstrom.hll_sketch_new(pgstrom.hll_hash(lo_custkey)))
Workers Planned: 2
-> Parallel Custom Scan (GpuPreAgg) on public.lineorder (cost=4991387.72..4991387.73 rows=1 width=32)
Output: (pgstrom.hll_sketch_new(pgstrom.hll_hash(lo_custkey)))
GPU Output: (pgstrom.hll_sketch_new(pgstrom.hll_hash(lo_custkey)))
GPU Setup: pgstrom.hll_hash(lo_custkey)
Reduction: NoGroup
Outer Scan: public.lineorder (cost=2833.33..4913260.79 rows=250006160 width=6)
GPU Preference: GPU0 (Tesla V100-PCIE-16GB)
GPUDirect SQL: enabled
Kernel Source: /var/lib/pgdata/pgsql_tmp/pgsql_tmp_strom_374786.6.gpu
Kernel Binary: /var/lib/pgdata/pgsql_tmp/pgsql_tmp_strom_374786.7.ptx
(15 rows)
集約関数hll_count()をCPUで実行する代わりに、Aggregateでは hll_merge() が実行されているのが分かります。
これは HLL Sketch である bytea データを受け取り、カーディナリティの推定値を出力する集約関数です。
HLL Sketchを生成するのは GpuPreAgg の役割で、ここでは、pgstrom.hll_hash() で生成したハッシュ値を pgstrom.hll_sketch_new() に渡して、lo_custkey列のHLL Sketchを生成しています。
なお、ここで生成されるHLL Sketchは既に部分集約が終わった状態のものですので、およそ2億レコードを処理した後のHLL Sketchを各ワーカーごとにそれぞれ1行だけ返却するという処理になります。
つまり、2億件のレコードを1件のHLL Sketchに集約するまではGPUで実行し、最終的にHLL Sketchをマージして推計値を集計するところはCPUで実行しているわけです。
このようなアルゴリズムの特性により、例えば、月次のデータごとに HLL Sketch を予め計算してデータベースに保存しておけば、キー値のカーディナリティを推定するためにテーブル全体をスキャンしなくても、差分データの HLL Sketch を計算し、保存していた HLL Sketch と合成するだけでキー値のカーディナリティを推定する事ができます。
例えば、以下のクエリは年次単位でHLL Sketchを計算し、年次ごとのHLL Sketchをマージする事で累積でのカーディナリティを推定しています。
これが人為的にlo_custkeyのカーディナリティが増加するよう調整したデータですが、時間経過とともに累計ユーザ数の推定値が増えている事が分かります。
=# select lo_orderdate / 10000 as year, hll_sketch(lo_custkey) as sketch
into pg_temp.annual
from lineorder group by 1;
SELECT 7
=# select year, hll_sketch_histogram(sketch) from pg_temp.annual order by year;
year | hll_sketch_histogram
------+-------------------------------------------------------
1992 | {0,0,0,0,0,0,0,0,0,22,73,132,118,82,39,26,12,2,4,2}
1993 | {0,0,0,0,0,0,0,0,0,9,59,118,125,96,50,30,15,2,6,2}
1994 | {0,0,0,0,0,0,0,0,0,4,33,111,133,113,53,36,17,4,6,2}
1995 | {0,0,0,0,0,0,0,0,0,2,21,99,131,121,62,42,18,5,7,3,1}
1996 | {0,0,0,0,0,0,0,0,0,1,17,84,119,131,73,50,20,5,7,4,1}
1997 | {0,0,0,0,0,0,0,0,0,0,14,71,118,128,82,53,23,10,7,4,2}
1998 | {0,0,0,0,0,0,0,0,0,0,13,64,114,126,86,61,23,11,8,4,2}
(7 rows)
=# select max_y, (select hll_merge(sketch) from pg_temp.annual where year < max_y)
from generate_series(1993,1999) max_y;
max_y | hll_merge
-------+-----------
1993 | 854093
1994 | 1052429
1995 | 1299916
1996 | 1514915
1997 | 1700274
1998 | 1889527
1999 | 2005437
(7 rows)
なお、hll_sketch_histogram()はHLL Sketchの生データを引数として受け取り、そのレジスタ値の分布をヒストグラムとして返す関数です。