connect with Fluentd
This chapter introduces the cooperation with Fluentd via Apache Arrow data format for the efficient importing of IoT/M2M log data.
Overview
In the technological domain known as IoT/M2M, various software has been developed to store and analyze the large amount of log data generated by devices such as cell phones, automobiles, and various sensors, as well as PCs and servers. This is because the data generated by a large number of devices from time-by-time tend to grow up huge, and special architecture/technology is required to process it in a practical amount of time.
PG-Strom's features are designed and implemented for high-speed processing of log data of such a scale.
On the other hand, it tends to be a time-consuming job to transfer and import these data into a database in order to make it searchable/summarizable on such a scale.
Therefore, PG-Strom includes a fluent-plugin-arrow-file module for Fluentd that outputs the data in Apache Arrow format, and tries to deal with the problem.
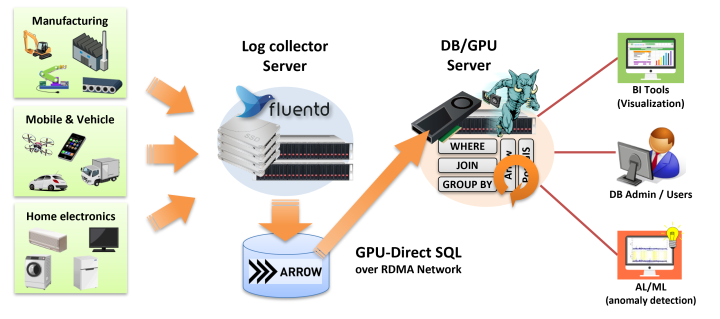
Fluentd is a log collection tool developed by Sadayuki Furuhashi. It is the de facto standard for collecting and storing a wide variety of log data, ranging from server logs like Syslog to device logs of IoT/M2M devices. Fluentd allows customization of the input/output and processing of log data by adding plugins written in Ruby. As of 2022, more than 800 plugins have been introduced on the official website.
PG-Strom can handle two types of data formats: PostgreSQL Heap format (transactional row data) and Apache Arrow format (structured column data). The Apache Arrow format is suitable for workloads like those in the IoT/M2M, where huge amounts of data are generated time-by-time.
arrow-file plugin
This chapter describes the approach to write out the log data collected by Fluentd in Apache Arrow format, and to refere it with PG-Strom.
We assume fluentd here, that is a stable version of Fluentd provided by Treasure Data.
PG-Strom includes the fluent-plugin-arrow-file module. This allows Fluentd to write out the log data it collects as an Apache Arrow format file with a specified schema structure.
Using PG-Strom's Arrow_Fdw, this Apache Arrow format file can be accessed as an foreign table.
In addition, GPU-Direct SQL allows to load these files extremely fast, if the storage system is appropriately configured.
This has the following advantages:
- There is no need to import data into the DB because PG-Strom directly accesses the files output by Fluentd.
- The data readout (I/O load) for the searching and summarizing process can be kept to a minimum because of the columnar data format.
- You can archive outdated log data only by moving files on the OS.
On the other hand, in cases that it takes a long time to store a certain size of log (for example, log generation is rare), another method such as outputting to a PostgreSQL table is suitable for more real-time log analysis. This is because the size of the Record Batch needs to be reasonably large to acquire the performance benefits of the Apache Arrow format.
Internals
There are several types of plugins for Fluentd: Input plugins to receive logs from outside, Parser plugins to shape the logs, Buffer plugins to temporarily store the received logs, and Output plugins to output the logs. The arrow-file plugin is categorized as Output plugin. It writes out a "chunk" of log data passed from the Buffer plugin in Apache Arrow format with the schema structure specified in the configuration.
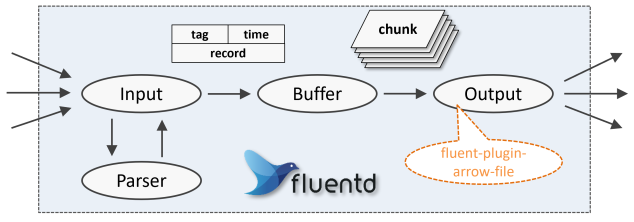
The Input/Parser plugin is responsible for converting the received logs into a common format so that the Buffer and Output plugins can handle the input data without being aware of its format.
The common format is a pair of tag, an identifier that can be used to sort the logs, a log timestamp time, and record, an associative array formed from the raw logs.
The arrow-file plugin writes to an Apache Arrow format file with the tag and time fields and each element of the record associative array as a column (some may be omitted).
Therefore, the output destination file name and schema definition information (mapping of associative array elements to columns/types) are mandatory configuration parameters.
Installation
Install the fluent-package package for Linux distribution you are using.
See the Install fluent-package for details.
$ curl -fsSL https://fluentd.cdn.cncf.io/sh/install-redhat-fluent-package6-lts.sh | sh
Next, download the source code for PG-Strom and build arrow-file plugin in the fluentd directory.
$ git clone https://github.com/heterodb/pg-strom.git
$ cd pg-strom/fluentd
$ make gem
$ sudo make install
To confirm that the Fluentd plugin is installed, run the following command.
$ /opt/fluent/bin/fluent-gem list | grep arrow
fluent-plugin-arrow-file (0.5)
Configuration
As mentioned above, the arrow-file plugin requires the output path of the file and the schema definition at least.
Due to the architecture of Fluentd's Write plugin, the arrow-file plugin writes data chunks passed from the Buffer plugin to a file as one Record Batch (this is called a Row Group in Parquet format, but it's roughly the same concept). When performing search and aggregation processing, a relatively larger Record Batch is easier to pull out high performance, but a size that does not fit into GPU memory is undesirable from the perspective of using PG-Strom. Since the arrow-file plugin creates a Record Batch for each data chunk passed from the Buffer plugin, the buffer size on the Buffer plugin side should be set accordingly. The default buffer size is set to 256MB. You should set the buffer size to around 256MB to 2GB as needed.
Also, previous versions of the arrow-file plugin appended a Record Batch to an already written Arrow file each time a data chunk was passed from the Buffer plugin, but from v0.5 onwards, the structure is 1 file = 1 Record Batch (1 Row Group). This is because libarrow and libparquet do not support appending, and exclusive access is required when using the generated files.
The configuration parameters for the arrow-file plugin are as follows:
path[type:String] (Required)- Specify the file path of the destination.
- This is a required parameter, and you can use placeholders shown below.
| Placeholders | Description |
|---|---|
%Y |
The current year expressed as a four-digit number. |
%y |
The current year expressed as a number in the last two digits of the year. |
%m |
A two-digit number representing the current month, 01-12. |
%d |
A two-digit number representing the current day from 01 to 31. |
%H |
A two-digit number representing the hour of the current time 00-23. |
%M |
A two-digit number representing the minute of the current time, 00-59. |
%S |
A two-digit number representing the second of the current time, 00-59. |
%p |
The PID of the current Fluentd process. |
The format string is evaluated when writing out a data chunk, and a new Apache Arrow format file (or Apache Parquet format file) with the specified name is created, and a file containing one Record Batch (or Row Group) is written to it. If a file with the same name exists, an attempt will be made to create a file with a different name, for example by adding a sequence number to the end of the file.
(Example) path /tmp/arrow_logs/my_logs_%y%m%d.%p.log
schema_defs[type:String] (Required)- Specify the schema definition of the Apache Arrow format file output by
fluent-plugin-arrow-file. - This is a required parameter, and define the schema structure using strings in the following format.
schema_defs := column_def1[,column_def2 ...]column_def := <column_name>=<column_type>[;<column_attrs>]<column_name>is the name of the column, which must match the key value of the associative array passed from Fluentd to arrow-file plugin.<column_type>is the data type of the column. See the following table.<column_attrs>is an additional attribute for columns. At this time, only the following attributes are supported.stat_enabled... The statistics for the configured columns will be collected and the maximum/minimum values for each Record Batch will be set as custom metadata in the form ofmax_values=...andmin_values=....stat_disabled... Disables per-column statistics that are collected by default in Parquet format. Ignored by Apache format.- Compression options: You can specify the compression algorithm for each column. One of the
snappy,gzip,brotli,zstd,lz4,lzo,bz2ornone(no compression) can be used.
(Example) schema_defs "ts=Timestamp;stat_enabled,dev_id=Uint32,temperature=Float32;bz2,humidity=Float32"
Data types supported by the arrow-file plugin
| Data types | Description |
|---|---|
Int8 Int16 Int32 Int64 |
Signed integer with the specified bit width. |
Uint8 Uint16 Uint32 Uint64 |
Unsigned integer with the specified bit width |
Float16 Float32 Float64 |
Floating point number with half-precision(16bit), single-precision(32bit) and double-precision(64bit). |
Decimal Decimal128 |
128-bit fixed decimal; 256-bit fixed decimal is currently not supported. |
Timestamp Timestamp[sec] Timestamp[ms] Timestamp[us] Timestamp[ns] |
Timestamp type with the specified precision. If the precision is omitted, it is treated the same as [us]. |
Time Time[sec] Time[ms] Time[us] Time[ns] |
Time type with the specified precision. If the precision is omitted, it is treated the same as [sec]. |
Date Date[Day] Date[ms] |
Date type with the specified precision. If the precision is omitted, it is treated the same as [day]. |
Utf8 |
String type. |
Ipaddr4 |
IP address(IPv4) type. This is represented as a FixedSizeBinary type with byteWidth=4 and custom metadata pg_type=pg_catalog.inet. |
Ipaddr6 |
IP address(IPv6) type. This is represented as a FixedSizeBinary type with byteWidth=16 and custom metadata pg_type=pg_catalog.inet. |
ts_column[type:String/ default: unspecified]- Specify a column name to set the timestamp value of the log passed from Fluentd (not from
record). - This parameter is usually a date-time type such as
Timestamp, and thestat_enabledattribute should also be specified to achieve fast search. tag_column[type:String/ default: unspecified]- Specify a column name to set the tag value of the log passed from Fluentd (not from
record). - This parameter is usually a string type such as
utf8. format[type:String/ default:arrow]- Specify the file format to be written by the
fluent-plugin-arrow-file. -
arrowmeans Apache Arrow format, andparquetmeans Apache Parquet format.- @ja
compression[type:String/ default:zstd]- Apache Parquet形式で使用する圧縮アルゴリズムを指定します。列単位での圧縮オプションがない場合は、こちらで指定した圧縮アルゴリズムが適用されます。
- 選択可能なアルゴリズムは
snappy、gzip、brotli、zstd、lz4、lzo、bz2、none(無圧縮)のいずれかです。
compression[type:String/ default:zstd]- Specifies the compression algorithm to use for Apache Parquet format. If no specific compression option is given on per-column configuration, the compression algorithm specified here will be applied.
- One of the
snappy,gzip,brotli,zstd,lz4,lzo,bz2ornone(uncompressed) can be used.
Example
As a simple example, this chapter shows a configuration for monitoring the log of a local Apache Httpd server, parsing it field by field, and writing it to an Apache Arrow format file.
By setting <source>, /var/log/httpd/access_log will be the data source. Then, the apache2 Parse plugin will cut out the fields: host, user, time, method, path, code, size, referer, agent.
The fields are then passed to the arrow-file plugin as an associative array. In schema_defs in <match>, the column definitions of the Apache Arrow file corresponding to the fields are set.
For simplicity of explanation, the chunk size is set to a maximum of 4MB / 200 lines in the <buffer> tag, and it is set to pass to the Output plugin in 10 seconds at most.
Example configuration of /etc/fluent/fluentd.conf
<source>
@type tail
path /var/log/httpd/access_log
pos_file /var/log/fluent/httpd_access.pos
tag httpd
format apache2
<parse>
@type apache2
expression /^(?<host>[^ ]*) [^ ]* (?<user>[^ ]*) \[(?<time>[^\]]*)\] "(?<method>\S+)(?: +(?<path>(?:[^\"]|\\.)*?)(?: +\S*)?)?" (?<code>[^ ]*) (?<size>[^ ]*)(?: "(?<referer>(?:[^\"]|\\.)*)" "(?<agent>(?:[^\"]|\\.)*)")?$/
time_format %d/%b/%Y:%H:%M:%S %z
</parse>
</source>
<match httpd>
@type arrow_file
path /tmp/mytest%Y%m%d.%p.arrow
schema_defs "ts=Timestamp[sec],host=Utf8,method=Utf8,path=Utf8,code=Int32,size=Int32,referer=Utf8,agent=Utf8"
ts_column "ts"
<buffer>
flush_interval 10s
chunk_limit_size 4MB
chunk_limit_records 200
</buffer>
</match>
Start the fluentd service.
$ sudo systemctl start fluentd
See the following output. The placeholder for /tmp/mytest%Y%m%d.%p.arrow set in path is replaced and the Apache Httpd log is written to /tmp/mytest20220124.3206341.arrow.
$ arrow2csv /tmp/mytest20220124.3206341.arrow --head --offset 300 --limit 10
"ts","host","method","path","code","size","referer","agent"
"2022-01-24 06:13:42","192.168.77.95","GET","/docs/ja/js/theme_extra.js",200,195,"http://buri/docs/ja/fluentd/","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36"
"2022-01-24 06:13:42","192.168.77.95","GET","/docs/ja/js/theme.js",200,4401,"http://buri/docs/ja/fluentd/","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36"
"2022-01-24 06:13:42","192.168.77.95","GET","/docs/ja/img/fluentd_overview.png",200,121459,"http://buri/docs/ja/fluentd/","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36"
"2022-01-24 06:13:42","192.168.77.95","GET","/docs/ja/search/main.js",200,3027,"http://buri/docs/ja/fluentd/","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36"
"2022-01-24 06:13:42","192.168.77.95","GET","/docs/ja/fonts/Lato/lato-regular.woff2",200,182708,"http://buri/docs/ja/css/theme.css","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36"
"2022-01-24 06:13:42","192.168.77.95","GET","/docs/ja/fonts/fontawesome-webfont.woff2?v=4.7.0",200,77160,"http://buri/docs/ja/css/theme.css","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36"
"2022-01-24 06:13:42","192.168.77.95","GET","/docs/ja/fonts/RobotoSlab/roboto-slab-v7-bold.woff2",200,67312,"http://buri/docs/ja/css/theme.css","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36"
"2022-01-24 06:13:42","192.168.77.95","GET","/docs/ja/fonts/Lato/lato-bold.woff2",200,184912,"http://buri/docs/ja/css/theme.css","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36"
"2022-01-24 06:13:43","192.168.77.95","GET","/docs/ja/search/worker.js",200,3724,"http://buri/docs/ja/fluentd/","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36"
"2022-01-24 06:13:43","192.168.77.95","GET","/docs/ja/img/favicon.ico",200,1150,"http://buri/docs/ja/fluentd/","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36"
Let's map the output file to PostgreSQL using PG-Strom's Arrow_Fdw.
postgres=# IMPORT FOREIGN SCHEMA mytest
FROM SERVER arrow_fdw INTO public
OPTIONS (file '/tmp/mytest20220124.3206341.arrow');
IMPORT FOREIGN SCHEMA
postgres=# SELECT ts, host, path FROM mytest WHERE code = 404;
ts | host | path
---------------------+---------------+----------------------
2022-01-24 12:02:06 | 192.168.77.73 | /~kaigai/ja/fluentd/
(1 row)
postgres=# EXPLAIN SELECT ts, host, path FROM mytest WHERE code = 404;
QUERY PLAN
------------------------------------------------------------------------------
Custom Scan (GpuScan) on mytest (cost=4026.12..4026.12 rows=3 width=72)
GPU Filter: (code = 404)
referenced: ts, host, path, code
files0: /tmp/mytest20220124.3206341.arrow (read: 128.00KB, size: 133.94KB)
(4 rows)
The example above shows how the generated Apache Arrow file can be mapped as an external table and accessed with SQL.
Search conditions can be given to search each field of the log formed on the Fluentd side. In the example above, the log with HTTP status code 404 is searched and one record is found.