Apache Arrow (列指向データストア)
概要
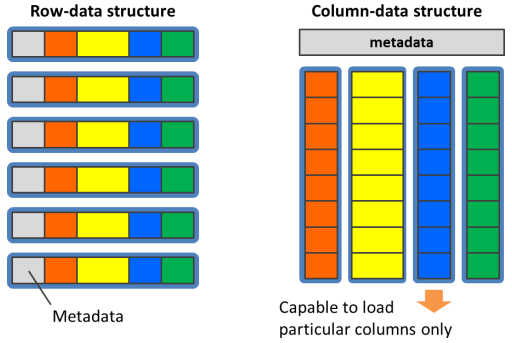
PostgreSQLのテーブルは内部的に8KBのブロック1と呼ばれる単位で編成され、ブロックは全ての属性及びメタデータを含むタプルと呼ばれるデータ構造を行単位で格納します。行を構成するデータが近傍に存在するため、これはINSERTやUPDATEの多いワークロードに有効ですが、一方で大量データの集計・解析ワークロードには不向きであるとされています。
通常、大量データの集計においてはテーブル内の全ての列を参照する事は珍しく、多くの場合には一部の列だけを参照するといった処理になりがちです。この場合、実際には参照されない列のデータをストレージからロードするために消費されるI/Oの帯域は全く無駄ですが、行単位で編成されたデータに対して特定の列だけを取り出すという操作は困難です。
逆に列単位でデータを編成した場合、INSERTやUPDATEの多いワークロードに対しては極端に不利ですが、大量データの集計・解析を行う際には被参照列だけをストレージからロードする事が可能になるため、I/Oの帯域を最大限に活用する事が可能です。 またプロセッサの処理効率の観点からも、列単位に編成されたデータは単純な配列であるかのように見えるため、GPUにとってはCoalesced Memory Accessというメモリバスの性能を最大限に引き出すアクセスパターンとなる事が期待できます。
Apache Arrowとは
Apache Arrowとは、構造化データを列形式で記録、交換するためのデータフォーマットです。 主にビッグデータ処理のためのアプリケーションソフトウェアが対応しているほか、CやC++、Pythonなどプログラミング言語向けのライブラリが整備されているため、自作のアプリケーションからApache Arrow形式を扱うよう設計する事も容易です。
![]()
Apache Arrow形式ファイルの内部には、データ構造を定義するスキーマ(Schema)部分と、スキーマに基づいて列データを記録する1個以上のレコードバッチ(RecordBatch)部分が存在します。データ型としては、整数や文字列(可変長)、日付時刻型などに対応しており、個々の列データはこれらデータ型に応じた内部表現を持っています。
Apache Arrow形式におけるデータ表現は、必ずしも全ての場合でPostgreSQLのデータ表現と一致している訳ではありません。例えば、Arrow形式ではタイムスタンプ型のエポックは1970-01-01で複数の精度を持つ事ができますが、PostgreSQLのエポックは2001-01-01でマイクロ秒の精度を持ちます。
Arrow_Fdwは外部テーブルを用いてApache Arrow形式ファイルをPostgreSQL上で読み出す事を可能にします。例えば、列ごとに100万件の列データが存在するレコードバッチを8個内包するArrow形式ファイルをArrow_Fdwを用いてマップした場合、この外部テーブルを介してArrowファイル上の800万件のデータへアクセスする事ができるようになります。
運用
外部テーブルの定義
通常、外部テーブルを作成するには以下の3ステップが必要です。
CREATE FOREIGN DATA WRAPPERコマンドにより外部データラッパを定義するCREATE SERVERコマンドにより外部サーバを定義するCREATE FOREIGN TABLEコマンドにより外部テーブルを定義する
このうち、最初の2ステップはCREATE EXTENSION pg_stromコマンドの実行に含まれており、個別に実行が必要なのは最後のCREATE FOREIGN TABLEのみです。
CREATE FOREIGN TABLE flogdata (
ts timestamp,
sensor_id int,
signal1 smallint,
signal2 smallint,
signal3 smallint,
signal4 smallint,
) SERVER arrow_fdw
OPTIONS (file '/path/to/logdata.arrow');
CREATE FOREIGN TABLE構文で指定した列のデータ型は、マップするArrow形式ファイルのスキーマ定義と厳密に一致している必要があります。
これ以外にも、Arrow_FdwはIMPORT FOREIGN SCHEMA構文を用いた便利な方法に対応しています。これは、Arrow形式ファイルの持つスキーマ情報を利用して、自動的にテーブル定義を生成するというものです。 以下のように、外部テーブル名とインポート先のスキーマ、およびOPTION句でArrow形式ファイルのパスを指定します。 Arrowファイルのスキーマ定義には、列ごとのデータ型と列名(オプション)が含まれており、これを用いて外部テーブルの定義を行います。
IMPORT FOREIGN SCHEMA flogdata
FROM SERVER arrow_fdw
INTO public
OPTIONS (file '/path/to/logdata.arrow');
外部テーブルオプション
Arrow_Fdwは以下のオプションに対応しています。
外部テーブルに対するオプション
file=PATHNAME- 外部テーブルにマップするArrowファイルを1個指定します。
files=PATHNAME1[,PATHNAME2...]- 外部テーブルにマップするArrowファイルをカンマ(,)区切りで複数指定します。
dir=DIRNAME- 指定したディレクトリに格納されている全てのファイルを外部テーブルにマップします。
suffix=SUFFIXdirオプションの指定時、例えば.arrowなど、特定の接尾句を持つファイルだけをマップします。parallel_workers=N_WORKERS- この外部テーブルの並列スキャンに使用する並列ワーカープロセスの数を指定します。一般的なテーブルにおける
parallel_workersストレージパラメータと同等の意味を持ちます。 pattern=PATTERNfile、files、またはdirオプションで指定されたファイルのうち、ワイルドカードを含むPATTERNにマッチしたものだけを外部テーブルにマップします。- ワイルドカードには以下のものを利用することができます。
-
?... 任意の1文字にマッチする。
-
*... 任意の0文字以上の文字列にマッチする。
-
${KEY}... 任意の0文字以上の文字列にマッチする。
-
@{KEY}... 任意の0文字以上の数値列にマッチする。
- このオプションには面白い使い方があり、ワイルドカードの
${KEY}や@{KEY}でマッチしたファイル名の一部分を、仮想列として参照することができます。詳しくは、'''Arrow_Fdwの仮想列'''を参照してください。
カラムに対するオプション
field=FIELD- そのカラムにマップするArrowファイルのフィールド名を指定します。
- デフォルトでは、この外部テーブルの列名と同じフィールドのうち、最も最初に出現したフィールドをマップします。
virtual=KEY- そのカラムが仮想列である事を指定します。
KEYはテーブルオプションのpatternオプションで指定されたパターン中のワイルドカードのキー名を指定します。 - 仮想列はファイル名パターンのうち
KEYにマッチした部分をクエリで参照することができます。 virtual_metadata=KEY- そのカラムが仮想列である事を指定します。
KEYはArrowファイルのCustomMetadataフィールドに埋め込まれたKEY-VALUEペアを指定します。指定したKEY-VALUEペアが見つからない場合、このカラムはNULL値を返します。 - ArrowファイルのCustomMetadataには、スキーマ(PostgreSQLのテーブルに相当)に埋め込まれるものと、フィールド(PostgreSQLの列に相当)に埋め込まれるものの二種類があります。
- 例えば、
lo_orderdate.max_valuesのように、KEY値の前に.文字で区切られたフィールド名を記述する事で、フィールドに埋め込まれたCustomMetadataを参照する事が出来ます。フィールド名がない場合は、スキーマに埋め込まれたKEY-VALUEペアであるとして扱われます。 virtual_metadata_split=KEY- そのカラムが仮想列である事を指定します。
KEYはArrowファイルのCustomMetadataフィールドに埋め込まれたKEY-VALUEペアを指定します。指定したKEY-VALUEペアが見つからない場合、このカラムはNULL値を返します。 virtual_metadataとの違いは、CustomMetadataフィールドの値をデリミタ(,)で区切り、それを個々のRecord Batchに先頭から順に当てはめて行くことです。例えば、指定したCustomMetadataの値がTokyo,Osaka,Kyoto,Yokohamaであった場合、RecordBatch-0から読み出した行では'Tokyo'が、RecordBatch-1から読み出した行では'Osaka'が、RecordBatch-2から読み出した行では'Osaka'がこの仮想列の値として表示されます。
データ型の対応
Arrow形式のデータ型と、PostgreSQLのデータ型は以下のように対応しています。
IntbitWidth属性の値に応じて、それぞれint1、int2、int4、int8のいずれかに対応。is_signed属性の値は無視されます。int1はPG-Stromによる独自拡張FloatingPointprecision属性の値に応じて、それぞれfloat2、float4、float8のいずれかに対応。float2はPG-Stromによる独自拡張Utf8,LargeUtf8text型に対応Binary,LargeBinarybytea型に対応Decimalnumeric型に対応Datedate型に対応。unit=Day相当となるように補正される。Timetime型に対応。unit=MicroSecond相当になるように補正される。Timestamptimestamp型に対応。unit=MicroSecond相当になるように補正される。Intervalinterval型に対応List,LargeList- 要素型の1次元配列型として表現される。
Struct- 複合型として表現される。対応する複合型は予め定義されていなければならない。
FixedSizeBinarybyteWidth属性の値に応じてchar(n)として表現される。- メタデータ
pg_type=TYPENAMEが指定されている場合、該当するデータ型を割り当てる場合がある。現時点では、inetおよびmacaddr型。 Union、Map、Duration- 現時点ではPostgreSQLデータ型への対応はなし。
EXPLAIN出力の読み方
EXPLAINコマンドを用いて、Arrow形式ファイルの読み出しに関する情報を出力する事ができます。
以下の例は、約503GBの大きさを持つArrow形式ファイルをマップしたf_lineorder外部テーブルを含むクエリ実行計画の出力です。
=# EXPLAIN
SELECT sum(lo_extendedprice*lo_discount) as revenue
FROM f_lineorder,date1
WHERE lo_orderdate = d_datekey
AND d_year = 1993
AND lo_discount between 1 and 3
AND lo_quantity < 25;
QUERY PLAN
--------------------------------------------------------------------------------
Aggregate (cost=14535261.08..14535261.09 rows=1 width=8)
-> Custom Scan (GpuPreAgg) on f_lineorder (cost=14535261.06..14535261.07 rows=1 width=32)
GPU Projection: pgstrom.psum(((f_lineorder.lo_extendedprice * f_lineorder.lo_discount))::bigint)
GPU Scan Quals: ((f_lineorder.lo_discount >= 1) AND (f_lineorder.lo_discount <= 3) AND (f_lineorder.lo_quantity < 25)) [rows: 5999990000 -> 9999983]
GPU Join Quals [1]: (f_lineorder.lo_orderdate = date1.d_datekey) ... [nrows: 9999983 -> 1428010]
GPU Outer Hash [1]: f_lineorder.lo_orderdate
GPU Inner Hash [1]: date1.d_datekey
referenced: lo_orderdate, lo_quantity, lo_extendedprice, lo_discount
file0: /opt/nvme/f_lineorder_s999.arrow (read: 89.41GB, size: 502.92GB)
GPU-Direct SQL: enabled (GPU-0)
-> Seq Scan on date1 (cost=0.00..78.95 rows=365 width=4)
Filter: (d_year = 1993)
(12 rows)
これを見るとCustom Scan (GpuPreAgg)がf_lineorder外部テーブルをスキャンしている事がわかります。 file0には外部テーブルの背後にあるファイル名/opt/nvme/f_lineorder_s999.arrowとそのサイズが表示されます。複数のファイルがマップされている場合には、file1、file2、... と各ファイル毎に表示されます。 referencedには実際に参照されている列の一覧が列挙されており、このクエリにおいてはlo_orderdate、lo_quantity、lo_extendedpriceおよびlo_discount列が参照されている事がわかります。
また、GPU-Direct SQL: enabled (GPU-0)の表示がある事から、f_lineorderのスキャンにはGPU-Direct SQL機構が用いられることが分かります。
VERBOSEオプションを付与する事で、より詳細な情報が出力されます。
=# EXPLAIN VERBOSE
SELECT sum(lo_extendedprice*lo_discount) as revenue
FROM f_lineorder,date1
WHERE lo_orderdate = d_datekey
AND d_year = 1993
AND lo_discount between 1 and 3
AND lo_quantity < 25;
QUERY PLAN
--------------------------------------------------------------------------------
Aggregate (cost=14535261.08..14535261.09 rows=1 width=8)
Output: pgstrom.sum_int((pgstrom.psum(((f_lineorder.lo_extendedprice * f_lineorder.lo_discount))::bigint)))
-> Custom Scan (GpuPreAgg) on public.f_lineorder (cost=14535261.06..14535261.07 rows=1 width=32)
Output: (pgstrom.psum(((f_lineorder.lo_extendedprice * f_lineorder.lo_discount))::bigint))
GPU Projection: pgstrom.psum(((f_lineorder.lo_extendedprice * f_lineorder.lo_discount))::bigint)
GPU Scan Quals: ((f_lineorder.lo_discount >= 1) AND (f_lineorder.lo_discount <= 3) AND (f_lineorder.lo_quantity < 25)) [rows: 5999990000 -> 9999983]
GPU Join Quals [1]: (f_lineorder.lo_orderdate = date1.d_datekey) ... [nrows: 9999983 -> 1428010]
GPU Outer Hash [1]: f_lineorder.lo_orderdate
GPU Inner Hash [1]: date1.d_datekey
referenced: lo_orderdate, lo_quantity, lo_extendedprice, lo_discount
file0: /opt/nvme/f_lineorder_s999.arrow (read: 89.41GB, size: 502.92GB)
lo_orderdate: 22.35GB
lo_quantity: 22.35GB
lo_extendedprice: 22.35GB
lo_discount: 22.35GB
GPU-Direct SQL: enabled (GPU-0)
KVars-Slot: <slot=0, type='int4', expr='f_lineorder.lo_discount'>, <slot=1, type='int4', expr='f_lineorder.lo_quantity'>, <slot=2, type='int8', expr='(f_lineorder.lo_extendedprice * f_lineorder.lo_discount)'>, <slot=3, type='int4', expr='f_lineorder.lo_extendedprice'>, <slot=4, type='int4', expr='f_lineorder.lo_orderdate'>, <slot=5, type='int4', expr='date1.d_datekey'>
KVecs-Buffer: nbytes: 51200, ndims: 3, items=[kvec0=<0x0000-27ff, type='int4', expr='lo_discount'>, kvec1=<0x2800-4fff, type='int4', expr='lo_quantity'>, kvec2=<0x5000-77ff, type='int4', expr='lo_extendedprice'>, kvec3=<0x7800-9fff, type='int4', expr='lo_orderdate'>, kvec4=<0xa000-c7ff, type='int4', expr='d_datekey'>]
LoadVars OpCode: {Packed items[0]={LoadVars(depth=0): kvars=[<slot=4, type='int4' resno=6(lo_orderdate)>, <slot=1, type='int4' resno=9(lo_quantity)>, <slot=3, type='int4' resno=10(lo_extendedprice)>, <slot=0, type='int4' resno=12(lo_discount)>]}, items[1]={LoadVars(depth=1): kvars=[<slot=5, type='int4' resno=1(d_datekey)>]}}
MoveVars OpCode: {Packed items[0]={MoveVars(depth=0): items=[<slot=0, offset=0x0000-27ff, type='int4', expr='lo_discount'>, <slot=3, offset=0x5000-77ff, type='int4', expr='lo_extendedprice'>, <slot=4, offset=0x7800-9fff, type='int4', expr='lo_orderdate'>]}}, items[1]={MoveVars(depth=1): items=[<offset=0x0000-27ff, type='int4', expr='lo_discount'>, <offset=0x5000-77ff, type='int4', expr='lo_extendedprice'>]}}}
Scan Quals OpCode: {Bool::AND args=[{Func(bool)::int4ge args=[{Var(int4): slot=0, expr='lo_discount'}, {Const(int4): value='1'}]}, {Func(bool)::int4le args=[{Var(int4): slot=0, expr='lo_discount'}, {Const(int4): value='3'}]}, {Func(bool)::int4lt args=[{Var(int4): slot=1, expr='lo_quantity'}, {Const(int4): value='25'}]}]}
Join Quals OpCode: {Packed items[1]={JoinQuals: {Func(bool)::int4eq args=[{Var(int4): kvec=0x7800-a000, expr='lo_orderdate'}, {Var(int4): slot=5, expr='d_datekey'}]}}}
Join HashValue OpCode: {Packed items[1]={HashValue arg={Var(int4): kvec=0x7800-a000, expr='lo_orderdate'}}}
Partial Aggregation OpCode: {AggFuncs <psum::int[slot=2, expr='(lo_extendedprice * lo_discount)']> arg={SaveExpr: <slot=2, type='int8'> arg={Func(int8)::int8 arg={Func(int4)::int4mul args=[{Var(int4): kvec=0x5000-7800, expr='lo_extendedprice'}, {Var(int4): kvec=0x0000-2800, expr='lo_discount'}]}}}}
Partial Function BufSz: 16
-> Seq Scan on public.date1 (cost=0.00..78.95 rows=365 width=4)
Output: date1.d_datekey
Filter: (date1.d_year = 1993)
(28 rows)
被参照列をロードする際に読み出すべき列データの大きさを、列ごとに表示しています。 lo_orderdate、lo_quantity、lo_extendedpriceおよびlo_discount列のロードには合計で89.41GBの読み出しが必要で、これはファイルサイズ502.93GBの17.8%に相当します。
Arrow_Fdwの仮想列
Arrow_Fdwはスキーマ構造に互換性のある複数のApache Arrowを一個の外部テーブルにマッピングすることができます。例えば、外部テーブルオプションにdir '/opt/arrow/mydata'を指定すると、そのディレクトリ配下に存在する全てのファイルをマッピングするようになります。
トランザクショナルなデータベースの内容をApache Arrowファイルに変換するときに年月や特定のカテゴリ毎に分けてファイル化し、それらを反映したファイル名を付けて保存する事はしばしば行われています。
例えば、以下の例をご覧ください。トランザクショナルなテーブルであるlineorderをlo_orderdateの年単位、およびlo_shipmodeのカテゴリ毎にArrowファイルへと変換しています。
$ for s in RAIL AIR TRUCK SHIP FOB MAIL;
do
for y in 1993 1994 1995 1996 1997;
do
pg2arrow -d ssbm -c "SELECT * FROM lineorder_small \
WHERE lo_orderdate between ${y}0101 and ${y}1231 \
AND lo_shipmode = '${s}'" \
-o /opt/arrow/mydata/f_lineorder_${y}_${s}.arrow
done
done
$ ls /opt/arrow/mydata/
f_lineorder_1993_AIR.arrow f_lineorder_1995_RAIL.arrow
f_lineorder_1993_FOB.arrow f_lineorder_1995_SHIP.arrow
f_lineorder_1993_MAIL.arrow f_lineorder_1995_TRUCK.arrow
f_lineorder_1993_RAIL.arrow f_lineorder_1996_AIR.arrow
f_lineorder_1993_SHIP.arrow f_lineorder_1996_FOB.arrow
f_lineorder_1993_TRUCK.arrow f_lineorder_1996_MAIL.arrow
f_lineorder_1994_AIR.arrow f_lineorder_1996_RAIL.arrow
f_lineorder_1994_FOB.arrow f_lineorder_1996_SHIP.arrow
f_lineorder_1994_MAIL.arrow f_lineorder_1996_TRUCK.arrow
f_lineorder_1994_RAIL.arrow f_lineorder_1997_AIR.arrow
f_lineorder_1994_SHIP.arrow f_lineorder_1997_FOB.arrow
f_lineorder_1994_TRUCK.arrow f_lineorder_1997_MAIL.arrow
f_lineorder_1995_AIR.arrow f_lineorder_1997_RAIL.arrow
f_lineorder_1995_FOB.arrow f_lineorder_1997_SHIP.arrow
f_lineorder_1995_MAIL.arrow f_lineorder_1997_TRUCK.arrow
これらのApache Arrowファイルは全て同じスキーマ構造を持っており、dirオプションを用いて1個の外部テーブルにマッピングできます。
また、データの生成時に絞り込みを行っているため、ファイル名に1995を含むファイルにはlo_orderdateが19950101~19951231の範囲のレコードしか含まれておらず、ファイル名にRAILを含むファイルにはlo_shipmodeがRAILのレコードしか含まれていません。
つまり、これら複数のArrowファイルをマップしたArrow_Fdw外部テーブルを定義したとしても、ファイル名に1995を含むファイルからデータを読み出している時には、lo_orderdateの値が19950101~19951231の範囲であることが事前に分かっており、それを利用した最適化が可能です。
Arrow_Fdwでは、外部テーブルオプションpatternを使用する事でファイル名の一部を列として参照する事ができます。これを仮想列と呼び、以下のように設定します。
=# IMPORT FOREIGN SCHEMA f_lineorder
FROM SERVER arrow_fdw INTO public
OPTIONS (dir '/opt/arrow/mydata', pattern 'f_lineorder_@{year}_${shipping}.arrow');
IMPORT FOREIGN SCHEMA
=# \d f_lineorder
Foreign table "public.f_lineorder"
Column | Type | Collation | Nullable | Default | FDW options
--------------------+---------------+-----------+----------+---------+----------------------
lo_orderkey | numeric | | | |
lo_linenumber | integer | | | |
lo_custkey | numeric | | | |
lo_partkey | integer | | | |
lo_suppkey | numeric | | | |
lo_orderdate | integer | | | |
lo_orderpriority | character(15) | | | |
lo_shippriority | character(1) | | | |
lo_quantity | numeric | | | |
lo_extendedprice | numeric | | | |
lo_ordertotalprice | numeric | | | |
lo_discount | numeric | | | |
lo_revenue | numeric | | | |
lo_supplycost | numeric | | | |
lo_tax | numeric | | | |
lo_commit_date | character(8) | | | |
lo_shipmode | character(10) | | | |
year | bigint | | | | (virtual 'year')
shipping | text | | | | (virtual 'shipping')
Server: arrow_fdw
FDW options: (dir '/opt/arrow/mydata', pattern 'f_lineorder_@{year}_${shipping}.arrow')
この外部テーブルオプションpatternには2つのワイルドカードが含まれています。
0文字以上の数字列にマッチする@{year}と、0文字以上の文字列にマッチする${shipping}です。
ファイル名のうち、この部分にマッチしたパターンは、それぞれ列オプションのvirtualで指定した部分で参照することができます。
この場合、IMPORT FOREIGN SCHEMAが自動的に列定義を加え、Arrowファイル自体に含まれているフィールドに加えて、ワイルドカード@{year}を参照する仮想列year(数値列であるためbigintデータ型)と、${shipping}を参照する仮想列shippingを追加しています。
これらの仮想列に対応するフィールドはArrowファイルには存在しませんが、例えば、ファイルf_lineorder_1994_AIR.arrowから読みだした行を処理するときにはyear列の値は1994に、shipping列の値は'AIR'になるわけです。
=# SELECT lo_orderkey, lo_orderdate, lo_shipmode, year, shipping
FROM f_lineorder
WHERE year = 1995 AND shipping = 'AIR'
LIMIT 10;
lo_orderkey | lo_orderdate | lo_shipmode | year | shipping
-------------+--------------+-------------+------+----------
637892 | 19950512 | AIR | 1995 | AIR
638243 | 19950930 | AIR | 1995 | AIR
638273 | 19951214 | AIR | 1995 | AIR
637443 | 19950805 | AIR | 1995 | AIR
637444 | 19950803 | AIR | 1995 | AIR
637510 | 19950831 | AIR | 1995 | AIR
637504 | 19950726 | AIR | 1995 | AIR
637863 | 19950802 | AIR | 1995 | AIR
637892 | 19950512 | AIR | 1995 | AIR
637987 | 19950211 | AIR | 1995 | AIR
(10 rows)
これは言い換えれば、Arrow_Fdw外部テーブルがマップしたArrowファイルを実際に読む前に、仮想列がどのような値になっているのかを知る事ができるという事です。この特徴を使えば、あるArrowファイルの読み出しの前に、検索条件から1件もマッチしない事が明らかである場合には、ファイルの読み出し自体をスキップする事が可能であるという事になります。
以下のクエリとそのEXPLAIN ANALYZE出力をご覧ください。
この集計クエリはf_lineorder外部テーブルを読み出し、いくつかの条件で絞り込んだ後、lo_extendedprice * lo_discountの合計値を集計します。
その時、WHERE year = 1994という条件句が付加されています。これは実質的にはWHERE lo_orderdate BETWEEN 19940101 AND 19942131と同じですが、yearは仮想列であるため、Arrowファイルを読み出す前にマッチする行が存在するかどうかを判定する事ができます。
実際、Stats-Hint:行を見ると、(year = 1994)という条件によって12個のRecord-Batchがロードされたものの、48個のRecord-Batchはスキップされています。これは単純ですがI/Oの負荷を軽減する手段として極めて有効です。
=# EXPLAIN ANALYZE
SELECT sum(lo_extendedprice*lo_discount) as revenue
FROM f_lineorder
WHERE year = 1994
AND lo_discount between 1 and 3
AND lo_quantity < 25;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------
Aggregate (cost=421987.07..421987.08 rows=1 width=32) (actual time=82.914..82.915 rows=1 loops=1)
-> Custom Scan (GpuPreAgg) on f_lineorder (cost=421987.05..421987.06 rows=1 width=32) \
(actual time=82.901..82.903 rows=2 loops=1)
GPU Projection: pgstrom.psum(((lo_extendedprice * lo_discount))::double precision)
GPU Scan Quals: ((year = 1994) AND (lo_discount <= '3'::numeric) AND \
(lo_quantity < '25'::numeric) AND \
(lo_discount >= '1'::numeric)) [plan: 65062080 -> 542, exec: 13001908 -> 1701726]
referenced: lo_quantity, lo_extendedprice, lo_discount, year
Stats-Hint: (year = 1994) [loaded: 12, skipped: 48]
file0: /opt/arrow/mydata/f_lineorder_1996_MAIL.arrow (read: 99.53MB, size: 427.16MB)
file1: /opt/arrow/mydata/f_lineorder_1996_SHIP.arrow (read: 99.52MB, size: 427.13MB)
file2: /opt/arrow/mydata/f_lineorder_1994_FOB.arrow (read: 99.18MB, size: 425.67MB)
: : : :
file27: /opt/arrow/mydata/f_lineorder_1997_MAIL.arrow (read: 99.23MB, size: 425.87MB)
file28: /opt/arrow/mydata/f_lineorder_1995_MAIL.arrow (read: 99.16MB, size: 425.58MB)
file29: /opt/arrow/mydata/f_lineorder_1993_TRUCK.arrow (read: 99.24MB, size: 425.91MB)
GPU-Direct SQL: enabled (N=2,GPU0,1; direct=76195, ntuples=13001908)
Planning Time: 2.402 ms
Execution Time: 83.857 ms
(39 rows)
Arrowファイルの作成方法
本節では、既にPostgreSQLデータベースに格納されているデータをApache Arrow形式に変換する方法を説明します。
PyArrow+Pandas
Arrow開発者コミュニティが開発を行っている PyArrow モジュールとPandasデータフレームの組合せを用いて、PostgreSQLデータベースの内容をArrow形式ファイルへと書き出す事ができます。
以下の例は、テーブルt0に格納されたデータを全て読込み、ファイル/tmp/t0.arrowへと書き出すというものです。
import pyarrow as pa
import pandas as pd
X = pd.read_sql(sql="SELECT * FROM t0", con="postgresql://localhost/postgres")
Y = pa.Table.from_pandas(X)
f = pa.RecordBatchFileWriter('/tmp/t0.arrow', Y.schema)
f.write_table(Y,1000000) # RecordBatch for each million rows
f.close()
ただし上記の方法は、SQLを介してPostgreSQLから読み出したデータベースの内容を一度メモリに保持するため、大量の行を一度に変換する場合には注意が必要です。
Pg2Arrow
一方、PG-Strom Development Teamが開発を行っている pg2arrow コマンドを使用して、PostgreSQLデータベースの内容をArrow形式ファイルへと書き出す事ができます。 このツールは比較的大量のデータをNVME-SSDなどストレージに書き出す事を念頭に設計されており、PostgreSQLデータベースから-s|--segment-sizeオプションで指定したサイズのデータを読み出すたびに、Arrow形式のレコードバッチ(Record Batch)としてファイルに書き出します。そのため、メモリ消費量は比較的リーズナブルな値となります。
pg2arrowコマンドはPG-Stromに同梱されており、PostgreSQL関連コマンドのインストール先ディレクトリに格納されます。
$ pg2arrow --help
Usage:
pg2arrow [OPTION] [database] [username]
General options:
-d, --dbname=DBNAME Database name to connect to
-c, --command=COMMAND SQL command to run
-t, --table=TABLENAME Equivalent to '-c SELECT * FROM TABLENAME'
(-c and -t are exclusive, either of them must be given)
--inner-join=SUB_COMMAND
--outer-join=SUB_COMMAND
-o, --output=FILENAME result file in Apache Arrow format
--append=FILENAME result Apache Arrow file to be appended
(--output and --append are exclusive. If neither of them
are given, it creates a temporary file.)
-S, --stat[=COLUMNS] embeds min/max statistics for each record batch
COLUMNS is a comma-separated list of the target
columns if partially enabled.
Arrow format options:
-s, --segment-size=SIZE size of record batch for each
Connection options:
-h, --host=HOSTNAME database server host
-p, --port=PORT database server port
-u, --user=USERNAME database user name
-w, --no-password never prompt for password
-W, --password force password prompt
Other options:
--dump=FILENAME dump information of arrow file
--progress shows progress of the job
--set=NAME:VALUE config option to set before SQL execution
--help shows this message
Report bugs to <pgstrom@heterodbcom>.
PostgreSQLへの接続パラメータはpsqlやpg_dumpと同様に、-hや-Uなどのオプションで指定します。 基本的なコマンドの使用方法は、-c|--commandオプションで指定したSQLをPostgreSQL上で実行し、その結果を-o|--outputで指定したファイルへArrow形式で書き出します。
-o|--outputオプションの代わりに--appendオプションを使用する事ができ、これは既存のApache Arrowファイルへの追記を意味します。この場合、追記されるApache Arrowファイルは指定したSQLの実行結果と完全に一致するスキーマ構造を持たねばなりません。
以下の例は、テーブルt0に格納されたデータを全て読込み、ファイル/tmp/t0.arrowへと書き出すというものです。
$ pg2arrow -U kaigai -d postgres -c "SELECT * FROM t0" -o /tmp/t0.arrow
開発者向けオプションですが、--dump <filename>でArrow形式ファイルのスキーマ定義やレコードバッチの位置とサイズを可読な形式で出力する事もできます。
--progressオプションを指定すると、処理の途中経過を表示する事が可能です。これは巨大なテーブルをApache Arrow形式に変換する際に有用です。
先進的な使い方
SSDtoGPUダイレクトSQL
Arrow_Fdw外部テーブルにマップされた全てのArrow形式ファイルが以下の条件を満たす場合には、列データの読み出しにSSD-to-GPUダイレクトSQLを使用する事ができます。
- Arrow形式ファイルがNVME-SSD区画上に置かれている。
- NVME-SSD区画はExt4ファイルシステムで構築されている。
- Arrow形式ファイルの総計が
pg_strom.nvme_strom_threshold設定を上回っている。
パーティション設定
Arrow_Fdw外部テーブルを、パーティションの一部として利用する事ができます。 通常のPostgreSQLテーブルと混在する事も可能ですが、Arrow_Fdw外部テーブルは書き込みに対応していない事に注意してください。 また、マップされたArrow形式ファイルに含まれるデータは、パーティションの境界条件と矛盾しないように設定してください。これはデータベース管理者の責任です。
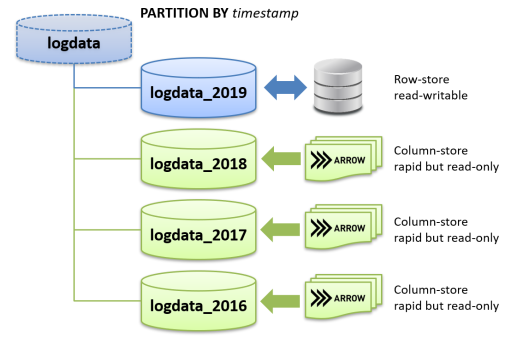
典型的な利用シーンは、長期間にわたり蓄積したログデータの処理です。
トランザクションデータと異なり、一般的にログデータは一度記録されたらその後更新削除されることはありません。 したがって、一定期間が経過したログデータは、読み出し専用ではあるものの集計処理が高速なArrow_Fdw外部テーブルに移し替えることで、集計・解析ワークロードの処理効率を引き上げる事が可能となります。また、ログデータにはほぼ間違いなくタイムスタンプが付与されている事から、月単位、週単位など、一定期間ごとにパーティション子テーブルを追加する事が可能です。
以下の例は、PostgreSQLテーブルとArrow_Fdw外部テーブルを混在させたパーティションテーブルを定義したものです。
書き込みが可能なPostgreSQLテーブルをデフォルトパーティションとして指定しておく事で、一定期間の経過後、DB運用を継続しながら過去のログデータだけをArrow_Fdw外部テーブルへ移す事が可能です。
CREATE TABLE lineorder (
lo_orderkey numeric,
lo_linenumber integer,
lo_custkey numeric,
lo_partkey integer,
lo_suppkey numeric,
lo_orderdate integer,
lo_orderpriority character(15),
lo_shippriority character(1),
lo_quantity numeric,
lo_extendedprice numeric,
lo_ordertotalprice numeric,
lo_discount numeric,
lo_revenue numeric,
lo_supplycost numeric,
lo_tax numeric,
lo_commit_date character(8),
lo_shipmode character(10)
) PARTITION BY RANGE (lo_orderdate);
CREATE TABLE lineorder__now PARTITION OF lineorder default;
CREATE FOREIGN TABLE lineorder__1993 PARTITION OF lineorder
FOR VALUES FROM (19930101) TO (19940101)
SERVER arrow_fdw OPTIONS (file '/opt/tmp/lineorder_1993.arrow');
CREATE FOREIGN TABLE lineorder__1994 PARTITION OF lineorder
FOR VALUES FROM (19940101) TO (19950101)
SERVER arrow_fdw OPTIONS (file '/opt/tmp/lineorder_1994.arrow');
CREATE FOREIGN TABLE lineorder__1995 PARTITION OF lineorder
FOR VALUES FROM (19950101) TO (19960101)
SERVER arrow_fdw OPTIONS (file '/opt/tmp/lineorder_1995.arrow');
CREATE FOREIGN TABLE lineorder__1996 PARTITION OF lineorder
FOR VALUES FROM (19960101) TO (19970101)
SERVER arrow_fdw OPTIONS (file '/opt/tmp/lineorder_1996.arrow');
このテーブルに対する問い合わせの実行計画は以下のようになります。 検索条件lo_orderdate between 19950701 and 19960630がパーティションの境界条件を含んでいる事から、子テーブルlineorder__1993とlineorder__1994は検索対象から排除され、他のテーブルだけを読み出すよう実行計画が作られています。
=# EXPLAIN
SELECT sum(lo_extendedprice*lo_discount) as revenue
FROM lineorder,date1
WHERE lo_orderdate = d_datekey
AND lo_orderdate between 19950701 and 19960630
AND lo_discount between 1 and 3
ABD lo_quantity < 25;
QUERY PLAN
--------------------------------------------------------------------------------
Aggregate (cost=172088.90..172088.91 rows=1 width=32)
-> Hash Join (cost=10548.86..172088.51 rows=77 width=64)
Hash Cond: (lineorder__1995.lo_orderdate = date1.d_datekey)
-> Append (cost=10444.35..171983.80 rows=77 width=67)
-> Custom Scan (GpuScan) on lineorder__1995 (cost=10444.35..33671.87 rows=38 width=68)
GPU Filter: ((lo_orderdate >= 19950701) AND (lo_orderdate <= 19960630) AND
(lo_discount >= '1'::numeric) AND (lo_discount <= '3'::numeric) AND
(lo_quantity < '25'::numeric))
referenced: lo_orderdate, lo_quantity, lo_extendedprice, lo_discount
files0: /opt/tmp/lineorder_1995.arrow (size: 892.57MB)
-> Custom Scan (GpuScan) on lineorder__1996 (cost=10444.62..33849.21 rows=38 width=68)
GPU Filter: ((lo_orderdate >= 19950701) AND (lo_orderdate <= 19960630) AND
(lo_discount >= '1'::numeric) AND (lo_discount <= '3'::numeric) AND
(lo_quantity < '25'::numeric))
referenced: lo_orderdate, lo_quantity, lo_extendedprice, lo_discount
files0: /opt/tmp/lineorder_1996.arrow (size: 897.87MB)
-> Custom Scan (GpuScan) on lineorder__now (cost=11561.33..104462.33 rows=1 width=18)
GPU Filter: ((lo_orderdate >= 19950701) AND (lo_orderdate <= 19960630) AND
(lo_discount >= '1'::numeric) AND (lo_discount <= '3'::numeric) AND
(lo_quantity < '25'::numeric))
-> Hash (cost=72.56..72.56 rows=2556 width=4)
-> Seq Scan on date1 (cost=0.00..72.56 rows=2556 width=4)
(16 rows)
この後、lineorder__nowテーブルから1997年のデータを抜き出し、これをArrow_Fdw外部テーブル側に移すには以下の操作を行います
$ pg2arrow -d sample -o /opt/tmp/lineorder_1997.arrow \
-c "SELECT * FROM lineorder WHERE lo_orderdate between 19970101 and 19971231"
pg2arrowコマンドにより、lineorderテーブルから1997年のデータだけを抜き出して、新しいArrow形式ファイルへ書き出します。
BEGIN;
--
-- remove rows in 1997 from the read-writable table
--
DELETE FROM lineorder WHERE lo_orderdate BETWEEN 19970101 AND 19971231;
--
-- define a new partition leaf which maps log-data in 1997
--
CREATE FOREIGN TABLE lineorder__1997 PARTITION OF lineorder
FOR VALUES FROM (19970101) TO (19980101)
SERVER arrow_fdw OPTIONS (file '/opt/tmp/lineorder_1997.arrow');
COMMIT;
この操作により、PostgreSQLテーブルであるlineorder__nowから1997年のデータを削除し、代わりに同一内容のArrow形式ファイル/opt/tmp/lineorder_1997.arrowを外部テーブルlineorder__1997としてマップしました。
-
正確には、4KB~32KBの範囲でビルド時に指定できます ↩