GPUキャッシュ
概要
GPUにはホストシステムのRAMとは独立なデバイスメモリが搭載されており、GPUで計算するにはPCI-Eバスなどを通じて、一旦、ホストシステムやストレージデバイスからデータをGPUデバイスメモリ側へ転送する必要があります。 PG-StromがSQLクエリをGPUで処理する場合も例外ではなく、内部的には、PostgreSQLテーブルから読み出したレコードをGPUへと転送し、その上でGPUでSQLの各種処理を実行します。 しかしこれらの処理には、多かれ少なかれテーブルの読み出しやデータの転送に時間を要します(多くの場合、GPUでの処理よりも遥かに長い時間の!)。
GPUキャッシュ(GPU Cache)とは、GPUデバイスメモリ上に予め領域を確保しておき、そこにPostgreSQLテーブルの複製を保持しておく機能です。
比較的データサイズの小さな(~10GB程度)データセットで、更新頻度が高いうえに、しばしばリアルタイムのデータに対して検索/分析系のSQLを実行するというパターンを意図しています。
後述するログベースの同期メカニズムにより、並列度の高いトランザクショナルなワークロードを妨げることなくGPUキャッシュを最新の状態に保つ事が可能です。 その一方で、検索/分析系のSQLを実行する際には既にGPU上にデータがロードされているため、改めてテーブルからレコードを読み出したり、PCI-Eバスを介してデータを転送したりする事なく、SQLワークロードを実行する事ができるようになります。
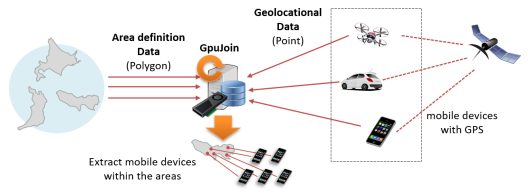
GPUキャッシュの典型的な利用シーンとしては、自動車や携帯電話といったモバイルデバイスの位置情報(現在位置)を時々刻々収集し、GPU版PostGISなどを用いて他のデータと突き合わせるといったケースが考えられます。 多数のデバイスから送出される位置情報の更新は極めて更新ヘビーなワークロードですが、一方で、最新の位置情報に基づいて検索/分析クエリを実行する必要もあるため、これら更新データを遅滞なくGPU側へ適用する必要があります。 データサイズには制約がありますが、GPUキャッシュは高頻度の更新と、高性能な検索/分析クエリの実行を両立する一つのオプションです。
アーキテクチャ
GPUキャッシュでは、並列度の高い更新系ワークロードに対応することと、検索/分析クエリが常に最新のデータを参照するという2つの要件をクリアする必要があります。
多くのシステムではCPUとGPUはPCI-Eバスを介して接続され、その通信には相応のレイテンシが発生します。 そのため、GPUキャッシュの対象テーブルが1行更新されるたびにGPUキャッシュを同期していては、トランザクション性能に大きな影響を与えてしまいます。
GPUキャッシュを作成すると、GPUデバイスメモリ上にキャッシュ用のメモリ領域を確保するだけでなく、ホスト側共有メモリ上にREDOログバッファを作成します。 テーブルの更新を伴うSQLコマンド(INSERT、UPDATE、DELETE)を実行すると、AFTER ROWトリガによって更新内容がREDOログバッファにコピーされますが、この処理はGPUへの呼び出しを伴わない、CPUとRAMだけで完結する処理ですので、トランザクション性能への影響はほとんどありません。
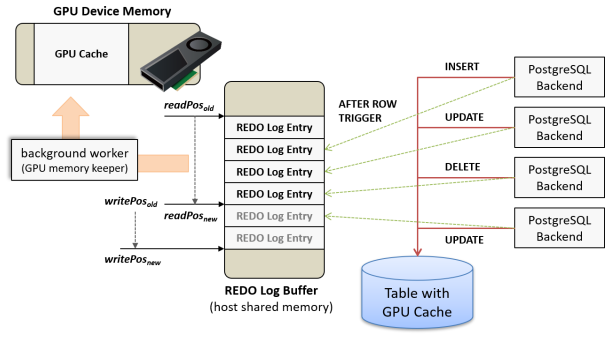
REDOログバッファに未適用のREDOログが一定量たまるか、最後の書き込みから一定時間が経過すると、バックグラウンドワーカープロセス(GPU memory keeper)によって未適用のREDOログはGPUへロードされ、更新差分をGPUキャッシュに適用します。 この時、REDOログはまとめてGPUに転送され、さらにGPUの数千プロセッサコアが並列にREDOログを適用するため、通常は処理遅延が問題となる事はありません。
検索/分析クエリでGPUキャッシュの対象テーブルを参照する際には、テーブルからデータを読み出してGPUにロードするのではなく、既にGPUデバイスメモリ上に割当て済みのGPUキャッシュをマッピングして利用します。これに先立って、クエリの実行開始時点で未適用のREDOログが存在する場合、これらは全て、検索/分析クエリの実行前にGPUキャッシュへ適用されます。 そのため、検索/分析クエリが対象のGPUキャッシュをスキャンした結果は、直接テーブルを参照した場合と同じ結果を返す事となり、問い合わせの一貫性は常に保持されています。
設定
GPUキャッシュを有効にするには、対象となるテーブルに対して
pgstrom.gpucache_sync_trigger()関数を実行するAFTER INSERT OR UPDATE OR DELETEの行トリガを設定します。
レプリケーションのスレーブ側でGPUキャッシュを使用する場合、このトリガの発行モードがALWAYSである事が必要です。
以下の例は、テーブル dpoints に対してGPUキャッシュを設定する例です。
=# create trigger row_sync after insert or update or delete on dpoints_even for row
execute function pgstrom.gpucache_sync_trigger();
=# alter table dpoints_even enable always trigger row_sync;
GPUキャッシュのカスタマイズ
GPUキャッシュの行トリガに引数として KEY=VALUE 形式のオプション文字列を与える事で、GPUキャッシュをカスタマイズする事ができます。 構文トリガの方ではありませんのでご注意ください。
例えば、以下のGPUキャッシュは行数の最大値が250万行、REDOログバッファのサイズを100MBとして作成しています。
=# create trigger row_sync after insert or update or delete on dpoints_even for row
execute function pgstrom.gpucache_sync_trigger('max_num_rows=2500000,redo_buffer_size=100m');
行トリガの引数に与える事のできるオプションは以下の通りです。
gpu_device_id=GPU_ID(default: 0)- GPUキャッシュを確保する対象のGPUデバイスIDを指定します。
max_num_rows=NROWS(default: 10485760)- GPUキャッシュ上に確保できる行数を指定します。
- PostgreSQLテーブルと同様に、GPUキャッシュでも可視性制御のためにコミット前の更新行を保持する必要があるため、ある程度の余裕を持って
max_num_rowsを指定する必要があります。なお、更新/削除された古いバージョンの行は、トランザクションのコミット後に解放されます。 redo_buffer_size=SIZE(default: 160m)- REDOログバッファのサイズを指定します。単位として、k、m、gを指定できる。
gpu_sync_interval=SECONDS(default: 5)- REDOログバッファへの最後の書き込みから SECONDS 秒経過すると、たとえ更新行数が少なくとも、REDOログをGPU側へ反映します。
gpu_sync_threshold=SIZE(default:redo_buffer_sizeの25%)- REDOログバッファの書き込みのうち、未反映分の大きさが SIZE バイトに達すると、GPU側にREDOログを反映します。
- 単位としてk、m、gを指定できる。
GPUキャッシュのオプション
GPUキャッシュに関連して、以下のPostgreSQL設定パラメータが定義されています。
pg_strom.enable_gpucache(default: on)- GPUキャッシュが利用可能である場合、検索/分析系のクエリでGPUキャッシュを使用するかどうかを制御します。
- この値が off になっていると、GPUキャッシュが存在していてもこれを無視し、テーブルから都度データを読み出そうとします。
- なお、本設定はトリガによるREDOログバッファへの追記には影響しません。
pg_strom.gpucache_auto_preload(default: NULL)- PostgreSQLの起動時/再起動時に、本設定パラメータで指定されたテーブルのGPUキャッシュを予め構築しておきます。
- 書式は
DATABASE_NAME.SCHEMA_NAME.TABLE_NAMEで、複数個のテーブルを指定する場合はこれをカンマ区切りで並べます。 - まだGPUデバイス上にGPUキャッシュが構築されていない場合、対象テーブルをフルスキャンしてGPU側へ転送するのは、最初にGPUキャッシュにアクセスしようと試みたPostgreSQLバックエンドプロセスの役割です。これは通常、相応の時間を要する処理ですが、このオプションにロードすべきテーブルを記載しておくことで、検索/分析クエリの初回実行時に長々と待たされる事を抑止できます。
- なお、この設定パラメータに '*' と指定した場合、GPUキャッシュを持つ全てのテーブルの内容を順にGPUへロードしようと試みます。この時、バックグラウンドワーカは全てのデータベースに順にアクセスしていく事となりますが、postmasterに再起動を促すため終了コード 1 を返します。
- 以下のように、サーバの起動ログに「GPUCache Startup Preloader」が終了コード 1 で終了したと出力されますが、これは異常ではありません
LOG: database system is ready to accept connections
LOG: background worker "GPUCache Startup Preloader" (PID 856418) exited with exit code 1
LOG: background worker "GPUCache Startup Preloader" (PID 856427) exited with exit code 1
LOG: create GpuCacheSharedState dpoints:164c95f71
LOG: gpucache: AllocMemory dpoints:164c95f71 (main_sz=772505600, extra_sz=0)
LOG: gpucache: auto preload 'public.dpoints' (DB: postgres)
LOG: create GpuCacheSharedState mytest:1773a589b
LOG: gpucache: auto preload 'public.mytest' (DB: postgres)
LOG: gpucache: AllocMemory mytest:1773a589b (main_sz=675028992, extra_sz=0)
運用
GPUキャッシュの利用を確認する
GPUキャッシュの参照は透過的に行われます。ユーザはキャッシュの有無を意識する必要はなく、PG-Stromが自動的に判定して処理を切り替えます。
以下のクエリ実行計画は、GPUキャッシュの設定されたテーブル dpoints への参照を含むものです。下から3行目の「GPU Cache」フィールドに、このテーブルのGPUキャッシュの基本的な情報が表示されており、このクエリでは dpoints テーブルを読み出すのではなく、GPUキャッシュを参照してクエリを実行する事がわかります。
なお、max_num_rowsに表示されているのはGPUキャッシュの保持できる最大の行数、mainに表示されているのはGPUキャッシュの固定長フィールド用の領域の大きさ、extraに表示されているのは可変長データ用の領域の大きさです。
=# explain
select pref, city, count(*)
from giscity g, dpoints d
where pref = 'Tokyo'
and st_contains(g.geom,st_makepoint(d.x, d.y))
group by pref, city;
QUERY PLAN
--------------------------------------------------------------------------------------------------------
HashAggregate (cost=5638809.75..5638859.99 rows=5024 width=29)
Group Key: g.pref, g.city
-> Custom Scan (GpuPreAgg) (cost=5638696.71..5638759.51 rows=5024 width=29)
Reduction: Local
Combined GpuJoin: enabled
GPU Preference: GPU0 (NVIDIA Tesla V100-PCIE-16GB)
-> Custom Scan (GpuJoin) on dpoints d (cost=631923.57..5606933.23 rows=50821573 width=21)
Outer Scan: dpoints d (cost=0.00..141628.18 rows=7999618 width=16)
Depth 1: GpuGiSTJoin(nrows 7999618...50821573)
HeapSize: 3251.36KB
IndexFilter: (g.geom ~ st_makepoint(d.x, d.y)) on giscity_geom_idx
JoinQuals: st_contains(g.geom, st_makepoint(d.x, d.y))
GPU Preference: GPU0 (NVIDIA Tesla V100-PCIE-16GB)
GPU Cache: NVIDIA Tesla V100-PCIE-16GB [max_num_rows: 12000000, main: 772.51M, extra: 0]
-> Seq Scan on giscity g (cost=0.00..8929.24 rows=6353 width=1883)
Filter: ((pref)::text = 'Tokyo'::text)
(16 rows)
GPUキャッシュの状態を確認する
GPUキャッシュの現在の状態を確認するにはpgstrom.gpucache_infoビューを使用します。
=# select * from pgstrom.gpucache_info ;
database_oid | database_name | table_oid | table_name | signature | refcnt | corrupted | gpu_main_sz | gpu_extra_sz | redo_write_ts | redo_write_nitems | redo_write_pos | redo_read_nitems | redo_read_pos | redo_sync_pos | config_options
--------------+---------------+-----------+------------+------------+--------+-----------+-------------+--------------+----------------------------+-------------------+----------------+------------------+---------------+---------------+------------------------------------------------------------------------------------------------------------------------
12728 | postgres | 25244 | mytest | 6295279771 | 3 | f | 675028992 | 0 | 2021-05-14 03:00:18.623503 | 500000 | 36000000 | 500000 | 36000000 | 36000000 | gpu_device_id=0,max_num_rows=10485760,redo_buffer_size=167772160,gpu_sync_interval=5000000,gpu_sync_threshold=41943040
12728 | postgres | 25262 | dpoints | 5985886065 | 3 | f | 772505600 | 0 | 2021-05-14 03:00:18.524627 | 8000000 | 576000192 | 8000000 | 576000192 | 576000192 | gpu_device_id=0,max_num_rows=12000000,redo_buffer_size=167772160,gpu_sync_interval=5000000,gpu_sync_threshold=41943040
(2 rows)
このビューで表示されるGPUキャッシュの状態は、その時点で初期ロードが終わっており、GPUデバイスメモリ上に領域が確保されているものだけである事に留意してください。
つまり、トリガ関数が設定されているが初期ロードが終わっていない(まだ誰もアクセスしていない)場合、潜在的に確保されうるGPUキャッシュはまだpgstrom.gpucache_infoには現れません。
各フィールドの意味は以下の通りです。
database_oid- GPUキャッシュを設定したテーブルの属するデータベースのOIDです
database_name- GPUキャッシュを設定したテーブルの属するデータベースの名前です
table_oid- GPUキャッシュを設定したテーブルのOIDです。必ずしも現在のデータベースとは限らない事に留意してください。
table_name- GPUキャッシュを設定したテーブルの名前です。必ずしも現在のデータベースとは限らない事に留意してください。
signature- GPUキャッシュの一意性を示すハッシュ値です。例えば
ALTER TABLEの前後などでこの値が変わる場合があります。
- GPUキャッシュの一意性を示すハッシュ値です。例えば
refcnt- GPUキャッシュの参照カウンタです。これは必ずしも最新の値を反映しているとは限りません。
corrupted- GPUキャッシュの内容が破損しているかどうかを示します。
gpu_main_sz- GPUキャッシュ上に確保された固定長データ用の領域のサイズです。
gpu_extra_sz- GPUキャッシュ上に確保された可変長データ用の領域のサイズです。
redo_write_ts- REDOログバッファを最後に更新した時刻です。
redo_write_nitems- REDOログバッファに書き込まれたREDOログの総数です。
redo_write_pos- REDOログバッファに書き込まれたREDOログの総バイト数です。
redo_read_nitems- REDOログバッファから読み出し、GPUに適用されたREDOログの総数です。
redo_read_pos- REDOログバッファから読み出し、GPUに適用されたREDOログの総バイト数です。
redo_sync_pos- REDOログバッファに書き込まれたREDOログのうち、既にGPUキャッシュへの適用をバックグラウンドワーカにリクエストした位置です。
- REDOログバッファの残り容量が逼迫してきた際に、多数のセッションが同時に非同期のリクエストを発生させる事を避けるため、内部的に使用されます。
config_options- GPUキャッシュのオプション文字列です。
GPUキャッシュの破損と復元
GPUキャッシュにmax_num_rowsで指定した以上の行数を挿入しようとしたり、可変長データのバッファ長が肥大化しすぎたり、
といった理由でGPUキャッシュにREDOログを適用できなかった場合、GPUキャッシュは破損(corrupted)状態に移行します。
一度GPUキャッシュが破損すると、これを手動で復旧するまでは、検索/分析系のクエリでGPUキャッシュを参照する事はなくなり、 また、テーブルの更新に際してもREDOログの記録を行わなくなります。 (運悪く、検索/分析系のクエリが実行を開始した後にGPUキャッシュが破損した場合、そのクエリはエラーを返す事があります。)
GPUバッファを破損状態から復元するのは pgstrom.gpucache_recovery(regclass) 関数です。
REDOログを適用できなかった原因を取り除いた上でこの関数を実行すると、再度、GPUキャッシュの初期ロードを行い、元の状態への
復旧を試みます。
例えば、max_num_rows で指定した以上の行数を挿入しようとした場合であれば、トリガの定義を変更して max_num_rows 設定を
拡大するか、テーブルから一部の行を削除した後で、pgstrom.gpucache_recovery()関数を実行するという事になります。