パーティション
本章ではPostgreSQLのパーティショニング機能とPG-Stromを併用する方法について説明します。 なお、本章の内容はPostgreSQL v11以降でPG-Stromを使用する場合にのみ有効です。
PostgreSQLのパーティション機能について、詳しくはPostgreSQL文書:テーブルのパーティショニングを参照してください。
概要
PostgreSQL v10においてパーティショニング機能がサポートされました。 これは、論理的には一個の大きなテーブルであるものを物理的により小さなテーブルに分割して格納する仕組みで、検索条件より明らかにスキャンの必要がないパーティション子テーブルをスキップしたり、ストレージを物理的に分散させる事でより広いI/O帯域を確保するなどの利点があります。
PostgreSQL v10では範囲パーティショニング、リストパーティショニングの2種類がサポートされ、さらにPostgreSQL v11ではハッシュパーティショニングに加え、パーティション同士のJOINがサポートされています。
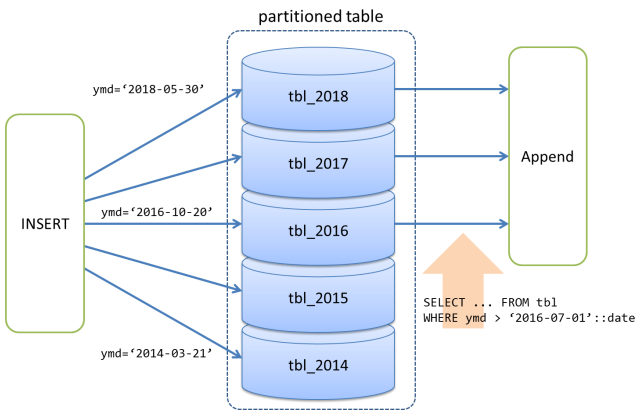
以下の図は、日付型(DATE型)のキー値を用いた範囲パーティショニングを示しています。
キー値2018-05-30を持つレコードは、パーティション子テーブルtbl_2018に振り分けられ、同様に、キー値2014-03-21を持つレコードは、パーティション子テーブルtbl_2014に振り分けられる・・・といった具合です。
パーティション化されたテーブルをスキャンする時、例えばWHERE ymd > '2016-07-01'::dateという条件句が付加されていると、tbl_2014およびtbl_2015に該当するレコードが存在しない事は自明ですので、PostgreSQLのオプティマイザはtbl_2016、tbl_2017、tbl_2018だけをスキャンし、その結果を結合するAppendノードを挟む事で、あたかも単一のテーブルからレコードを読み出したかのように振舞う実行計画を作成します。
PostgreSQLのパーティショニングとPG-Stromを併用する場合、まず、スキャンが必要であるとオプティマイザが判断したパーティション子テーブルのスキャンに対し、個々に実行コストを推定した上でGpuScanが選択される事があります。この場合、GpuScanの実行結果をAppendノードで束ねる事になります。
ただ、パーティションテーブルのスキャンに続き、JOINやGROUP BYなどPG-Stromで高速化が可能な処理を実行する場合には、最適化の観点から検討が必要です。
例えば、パーティション化されていないテーブルをスキャンして別のテーブルとJOINし、GROUP BYによる集計結果を出力する場合、条件が揃えば、各ステップ間のデータ交換はGPUデバイスメモリ上で行う事ができます。これはGPUとCPUの間のデータ移動を最小化するという観点から、最もPG-Stromが得意とするワークロードです。
一方、パーティション化されたテーブルに対して同様の処理を行う場合、テーブルのスキャンとJOINやGROUP BYの間にAppend処理が挟まってしまうのが課題です。この実行計画の下では、GpuScanが処理したデータを一度ホストシステムへ転送し、Append処理を行った上で、その後のGpuJoinやGpuPreAgg処理を行うために再びデータをGPUへ転送する事になります。これは決して効率の良い処理ではありません。
このようなCPU-GPU間のデータのピンポンを避けるため、PG-Stromは可能な限りJOINやGROUP BYをAppendよりも先に実行できるようプッシュダウンを試みます。
プッシュダウンが成功れば、データ交換を効率化できるだけでなく、特にGROUP BY処理によって行数を大幅に削減する事が可能となるため、Append処理を実行するホストシステムの負荷を顕著に減らす事になります。
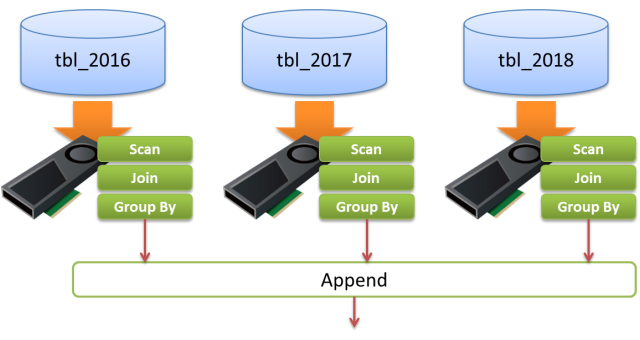
以下の例は、日付型(date型)のフィールドymdをキーとして年単位でパーティション子テーブルを設定しているptに対して、JOINとGROUP BYを含むクエリを投入した時の実行計画です。
検索条件により2016年以前のデータを含むパーティション子テーブルのスキャンは自明に排除され、さらにpt_2017、pt_2018、pt_2019各テーブルのJOINとGROUP BY処理が一体となってAppendの前に実行されている事が分かります。
# EXPLAIN SELECT cat,count(*),avg(ax)
FROM pt NATURAL JOIN t1
WHERE ymd > '2017-01-01'::date
GROUP BY cat;
QUERY PLAN
--------------------------------------------------------------------------------
HashAggregate (cost=196410.07..196412.57 rows=200 width=48)
Group Key: pt_2017.cat
-> Gather (cost=66085.69..196389.07 rows=1200 width=72)
Workers Planned: 2
-> Parallel Append (cost=65085.69..195269.07 rows=600 width=72)
-> Parallel Custom Scan (GpuPreAgg) (cost=65085.69..65089.69 rows=200 width=72)
Reduction: Local
Combined GpuJoin: enabled
-> Parallel Custom Scan (GpuJoin) on pt_2017 (cost=32296.64..74474.20 rows=1050772 width=40)
Outer Scan: pt_2017 (cost=28540.80..66891.11 rows=1050772 width=36)
Outer Scan Filter: (ymd > '2017-01-01'::date)
Depth 1: GpuHashJoin (nrows 1050772...2521854)
HashKeys: pt_2017.aid
JoinQuals: (pt_2017.aid = t1.aid)
KDS-Hash (size: 10.78MB)
-> Seq Scan on t1 (cost=0.00..1935.00 rows=100000 width=12)
-> Parallel Custom Scan (GpuPreAgg) (cost=65078.35..65082.35 rows=200 width=72)
Reduction: Local
Combined GpuJoin: enabled
-> Parallel Custom Scan (GpuJoin) on pt_2018 (cost=32296.65..74465.75 rows=1050649 width=40)
Outer Scan: pt_2018 (cost=28540.81..66883.43 rows=1050649 width=36)
Outer Scan Filter: (ymd > '2017-01-01'::date)
Depth 1: GpuHashJoin (nrows 1050649...2521557)
HashKeys: pt_2018.aid
JoinQuals: (pt_2018.aid = t1.aid)
KDS-Hash (size: 10.78MB)
-> Seq Scan on t1 (cost=0.00..1935.00 rows=100000 width=12)
-> Parallel Custom Scan (GpuPreAgg) (cost=65093.03..65097.03 rows=200 width=72)
Reduction: Local
Combined GpuJoin: enabled
-> Parallel Custom Scan (GpuJoin) on pt_2019 (cost=32296.65..74482.64 rows=1050896 width=40)
Outer Scan: pt_2019 (cost=28540.80..66898.79 rows=1050896 width=36)
Outer Scan Filter: (ymd > '2017-01-01'::date)
Depth 1: GpuHashJoin (nrows 1050896...2522151)
HashKeys: pt_2019.aid
JoinQuals: (pt_2019.aid = t1.aid)
KDS-Hash (size: 10.78MB)
-> Seq Scan on t1 (cost=0.00..1935.00 rows=100000 width=12)
(38 rows)
設定と運用
以下のGUCパラメータにより、PG-StromはJOINやGROUP BYのパーティション子テーブルへのプッシュダウンを制御します。
| パラメータ名 | 型 | 初期値 | 説明 |
|---|---|---|---|
pg_strom.enable_partitionwise_gpujoin |
bool |
on |
GpuJoinを各パーティションの要素へプッシュダウンするかどうかを制御する。PostgreSQL v10以降でのみ対応。 |
pg_strom.enable_partitionwise_gpupreagg |
bool |
on |
GpuPreAggを各パーティションの要素へプッシュダウンするかどうかを制御する。PostgreSQL v10以降でのみ対応。 |
これらパラメータの初期値はonですが、これをoffにした場合、プッシュダウン処理は行われません。
EXPLAINコマンドで前節のクエリの実行計画を表示したところ、実行計画は以下のように変化しています。 パーティション子テーブルのスキャンにはGpuScanが使用されていますが、その処理結果は一度ホストシステムに返され、Appendによって結合された後、再びGpuJoinを処理するためにGPUへと転送されます。
postgres=# set pg_strom.enable_partitionwise_gpujoin = off;
SET
postgres=# set pg_strom.enable_partitionwise_gpupreagg = off;
SET
postgres=# EXPLAIN SELECT cat,count(*),avg(ax) FROM pt NATURAL JOIN t1 WHERE ymd > '2017-01-01'::date group by cat;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------
Finalize GroupAggregate (cost=341392.92..341399.42 rows=200 width=48)
Group Key: pt.cat
-> Sort (cost=341392.92..341393.92 rows=400 width=72)
Sort Key: pt.cat
-> Gather (cost=341333.63..341375.63 rows=400 width=72)
Workers Planned: 2
-> Partial HashAggregate (cost=340333.63..340335.63 rows=200 width=72)
Group Key: pt.cat
-> Parallel Custom Scan (GpuJoin) (cost=283591.92..283591.92 rows=7565562 width=40)
Depth 1: GpuHashJoin (nrows 3152318...7565562)
HashKeys: pt.aid
JoinQuals: (pt.aid = t1.aid)
KDS-Hash (size: 10.78MB)
-> Append (cost=28540.80..200673.34 rows=3152318 width=36)
-> Parallel Custom Scan (GpuScan) on pt_2017 (cost=28540.80..66891.11 rows=1050772 width=36)
GPU Filter: (ymd > '2017-01-01'::date)
-> Parallel Custom Scan (GpuScan) on pt_2018 (cost=28540.81..66883.43 rows=1050649 width=36)
GPU Filter: (ymd > '2017-01-01'::date)
-> Parallel Custom Scan (GpuScan) on pt_2019 (cost=28540.80..66898.79 rows=1050896 width=36)
GPU Filter: (ymd > '2017-01-01'::date)
-> Seq Scan on t1 (cost=0.00..1935.00 rows=100000 width=12)
(21 rows)
SSDとGPUの配置に関する考慮
PostgreSQLのパーティショニングとSSD-to-GPUダイレクトSQL実行を併用する場合、各パーティション子テーブルがデータブロックを保存するNVMe-SSDストレージの物理的な配置には特に注意が必要です。
制限事項
実験的機能
GpuJoinとGpuPreAggのパーティション子テーブルへのプッシュダウンは、現時点では実験的な機能であり、予期せぬ不具合やクラッシュを引き起こす可能性があります。
その場合はpg_strom.enable_partitionwise_gpujoinやpg_strom.enable_partitionwise_gpupreaggを用いて当該機能を無効化すると共に、PG-Strom Issuesへ障害レポートをお願いします。