PG-Strom v3.0リリース
概要
PG-Strom v3.0における主要な変更は点は以下の通りです。
- NVIDIA GPUDirect Storage (cuFile) に対応しました。
- いくつかのPostGIS関数がGPUで実行可能となりました。
- GiSTインデックスを使用したGpuJoinに対応しました。
- 新たにGPUキャッシュ機能が実装されました。
- ユーザ定義のGPUデータ型/関数/演算子に対応しました。(実験的)
- ソフトウェアライセンスをGPLv2からPostgreSQLライセンスへと切り替えました。
動作環境
- PostgreSQL v11, v12, v13
- CUDA Toolkit 11.2 以降
- CUDA ToolkitのサポートするLinuxディストリビューション
- Intel x86 64bit アーキテクチャ(x86_64)
- NVIDIA GPU CC 6.0 以降 (Pascal以降)
NVIDIA GPUDirect Storage
GPUダイレクトSQL用のドライバとして、従来の nvme_strom カーネルモジュールに加えて、 NVIDIAが開発を進めているGPUDirect Storageにも対応しました。
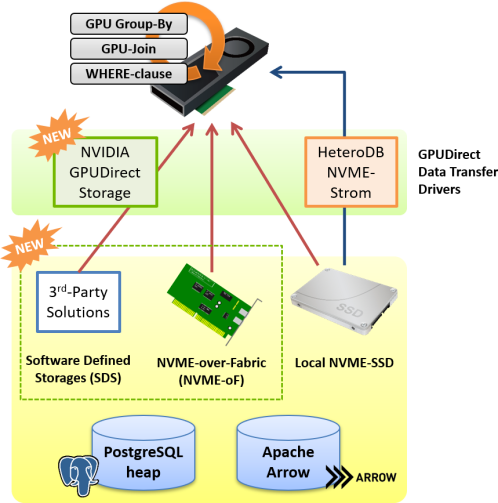
どちらのドライバも概ね同等の機能、性能を有していますが、GPUDirect Storageの対応により、従来からのローカルNVME-SSDに加えて、NVME-oF(NVME over Fabrics)デバイスやSDS(Software Defined Storage)デバイス、およびその上に構築された共有ファイルシステムからのGPUダイレクトSQLにも対応する事となり、より大規模で柔軟なストレージ構成を取る事が可能になります。
GPUDirect SQLは、PostgreSQL標準のHeapテーブルとApache Arrowファイルの読み出しに利用する事ができ、いずれの場合においても、テーブルスキャンがボトルネックとなるようなワークロードにおいて顕著な高速化が期待できます。
以下の測定結果は、GPU 1台とNVME-SSD 4台を用いて、SSBM(Star Schema Benchmark)ワークロードをGPUDirect SQLをGPUDirect Storageドライバの下で実行したものですが、PostgreSQL heapとApache Arrowのいずれのケースにおいても、単位時間あたりのデータ処理件数はPostgreSQLに比べ大幅に改善している事が分かります。
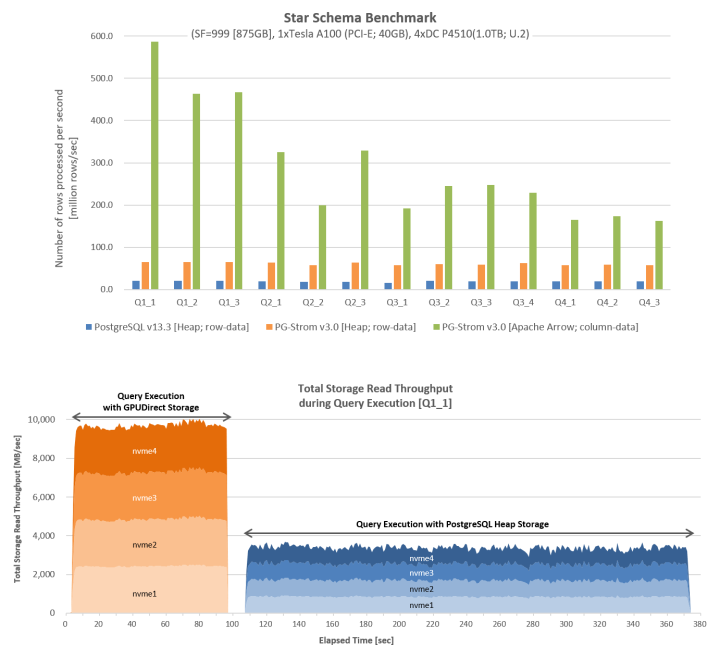
また、クエリを実行中のNVME-SSDからの読み出しスループットを比較してみると、ファイルシステムを介した読出し(PostgreSQL Heap Storage)に比べ、GPUDirect Storageを使用した場合にはハードウェア限界に近い性能値を引き出せている事が分かります。
GPU版PostGISとGiSTインデックス
いくつかのPostGIS関数にGPU版を実装しました。 条件句でこれらのPostGIS関数が使用されている場合、PG-StromはGPU側でこれを実行するようGPUプログラムを自動生成します。
GPU版PostGISの主たるターゲットは、携帯電話や自動車といった移動体デバイスの最新の位置情報(Real-time Location Data)と、市区町村や学区の境界といった領域(Area Definition Data)との間で行われる突合処理です。
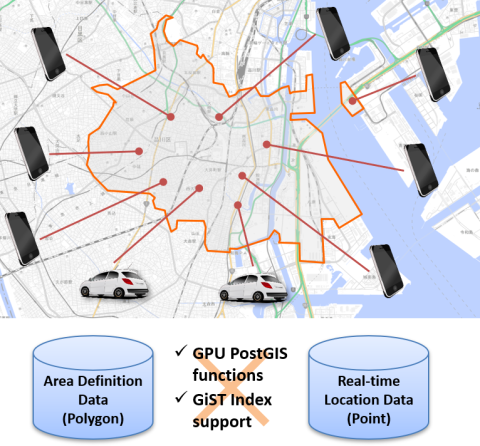
例えば、一定のエリア内に存在する携帯電話に広告を配信したい時、一定のエリア内に存在する自動車に渋滞情報を配信したい時など、位置をキーとして該当するデバイスを検索する処理に効果を発揮します。
以下の例は、東京近郊エリアを包含する矩形領域内にランダムな1600万個の点データを作成し、市区町村ごとにその領域内に含まれる点の数をカウントするという処理の応答時間を計測したものです。 通常のPostGISとGiSTインデックスの組み合わせでは160秒以上を要した処理が、GPU版PostGISとGiSTインデックスの組み合わせにおいては、僅か0.830秒で応答しています。

GPUキャッシュ
GPUデバイスメモリ上に予め領域を確保しておき、対象となるテーブルの複製を保持しておく機能です。 比較的小規模のデータサイズ(~10GB程度)で、更新頻度の高いデータに対して分析/検索系のクエリを効率よく実行するために設計されました。 分析/検索系クエリの実行時には、GPU上のキャッシュを参照する事で、テーブルからデータを読み出す事なくGPUでSQLワークロードを処理します。
これは典型的には、数百万デバイスのリアルタイムデータをGPU上に保持しておき、タイムスタンプや位置情報の更新が高頻度で発生するといったワークロードです。
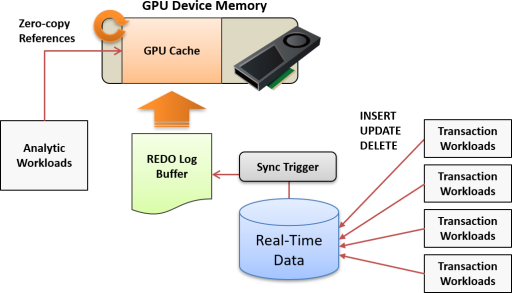
GPUキャッシュが設定されたテーブルを更新すると、その更新履歴をオンメモリのREDOログバッファに格納し、それを一定間隔か、または分析/検索系ワークロードの実行前にGPUキャッシュ側に反映します。 この仕組みにより、高頻度での更新と、GPUキャッシュとの整合性とを両立しています。
ユーザ定義のGPUデータ型/関数
ユーザ定義のGPUデータ型/関数を追加するためのAPIを新たに提供します。 これにより、PG-Strom自体には手を加えることなく、ニッチな用途のデータ型やそれを処理するためのSQL関数をユーザが独自に定義、実装する事が可能となりました。
Notice
本APIは実験的ステータスであり、将来のバージョンで予告なく変更される可能性があります。 また、本APIの利用にはPG-Strom内部構造を十分に理解している事が前提ですので、ドキュメントは提供されていません。
PostgreSQLライセンスの採用
PG-Strom v3.0以降ではPostgreSQLライセンスを採用します。
歴史的な経緯により、これまでのPG-StromではGPLv2を採用していましたが、PG-Stromコア機能や周辺ツールと組み合わせたソリューション開発にライセンス体系が障害になるとの声を複数いただいていました。
その他の変更
- 独自に
int1(8bit整数) データ型、および関連する演算子に対応しました。 pg2arrowに--inner-joinおよび--outer-joinオプションを追加しました。PostgreSQLの列数制限を越えた数の列を持つApache Arrowファイルを生成できるようになります。- マルチGPU環境では、GPUごとに専用のGPU Memory Keeperバックグラウンドワーカーが立ち上がるようになりました。
- PostgreSQL v13.x に対応しました。
- CUDA 11.2 および Ampere世代のGPUに対応しました。
- ScaleFlux社のComputational Storage製品CSD2000シリーズでのGPUDirect SQLに対応しました(cuFileドライバのみ)
- 雑多なバグの修正
廃止された機能
- PostgreSQL v10.x 系列のサポートが廃止されました。
- Pythonスクリプトとのデータ連携機能(PyStrom)が廃止されました。