PG-Strom v5.0リリース
概要
PG-Strom v5.0における主要な変更は点は以下の通りです。
- コードベースを一新し、従来の設計における問題点を改良しました。
- プロセスモデルがマルチプロセスからマルチスレッドになりました。これにより、GPUリソースの消費量を削減し、タスクスイッチングが軽量になりました。
- GPUデバイスコードはCUDA C++で動的生成されたネイティブコードから疑似コードへと置き換えられました。これにより、実行時コンパイル(NVRTC)が不要となりクエリの応答速度が向上したほか、将来的にCSD(Computational Storage Drive)やDPU(Data Processing Unit)でワークロードを実行するための設計変更です。
- GPU-CacheはCUDAマネージドメモリ上に展開されるようになりました。これにより、GPUデバイスメモリのオーバーコミットが可能になります。
- GPUデバイスコード上のPostgreSQLデータ型の表現が、Coalesced Memory Accessを意識したレイアウトに変わりました。
- GpuPreAggでのGROUP BY処理が一新され、全般的な処理速度が向上しました。
- GpuJoinの段数が深くなっても、タプルの展開は一回だけで済むようになりました。
- Arrow_FdwおよびPg2Arrowがmin/max統計値付きのArrowファイルに対応しました。
- ネットワークパケットをキャプチャするPcap2Arrowツール、およびArrowファイルをCSV出力するarrow2csvツールを追加しました。
動作環境
- PostgreSQL v15.x, v16.x
- CUDA Toolkit 12.2 以降
- CUDA ToolkitのサポートするLinuxディストリビューション
- Intel x86 64bit アーキテクチャ(x86_64)
- NVIDIA GPU CC 6.0 以降 (Pascal以降; Volta以降を推奨)
プロセスモデルの変更
v5.0ではマルチスレッドのバックグラウンドワーカープロセス(PG-Strom GPU Service)がGPUのリソース管理やタスク投入を統括するようになり、PostgreSQLの各バックグラウンドプロセスはIPCを通じてGPU Serviceへリクエストを送出し、結果を受け取る形に改められました。
v3.x系列まではPostgreSQLバックエンドプロセスが個別にGPUを制御していました。この設計は、かつてCUDAやPG-Stromのソフトウェア品質が十分でない時代に問題箇所の特定を容易にするという利点があったものの、データベースセッション数が増加すると極端にGPUリソースを消費し、またタスク切り替えの観点からも非推奨とされるソフトウェア構造でした。
この設計変更により、PG-Strom v5.0は同時実行数の増加に対して頑強になった他、高負荷なGPUタスクの実行性能が向上しています。
疑似コードの導入
PG-Strom v5.0では、SQLから独自の『疑似コード』を生成するようになり、GPUデバイスコードはこの『疑似コード』を実行するインタプリタとして働きます。v3.x系列のようにCUDA C++のネイティブコードを生成するわけではありません。 これは一見、性能低下の要因と見えるかもしれません。しかし、元々動的コード生成の対象となっていたのはWHERE句などクエリの度に変化するごく一部分だけであり、大半の実装は静的にビルドされていたほか、NVRTCによる実行時コンパイルの処理(150ms~程度)を省略できるようになったため、応答時間の改善に寄与しています。
『疑似コード』はEXPLAIN VERBOSEによって表示される低レベルなコマンドセットで、例えば、以下のようにWHERE句にlo_quantity > 10という演算式を含むクエリは、Scan Quals OpCodeとしてlo_quantity列と定数10との大小関係を比較するnumeric_gt関数を呼び出すよう処理が定義されています。
postgres=# explain verbose select count(*), sum(lo_quantity), lo_shipmode from lineorder where lo_quantity > 10 group by lo_shipmode;
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
HashAggregate (cost=3242387.01..3242387.10 rows=7 width=51)
Output: pgstrom.fcount((pgstrom.nrows())), pgstrom.sum_fp_num((pgstrom.psum((lo_quantity)::double precision))), lo_shipmode
Group Key: lineorder.lo_shipmode
-> Custom Scan (GpuPreAgg) on public.lineorder (cost=3242386.89..3242386.96 rows=7 width=51)
Output: (pgstrom.nrows()), (pgstrom.psum((lo_quantity)::double precision)), lo_shipmode
GPU Projection: pgstrom.nrows(), pgstrom.psum((lo_quantity)::double precision), lo_shipmode
GPU Scan Quals: (lo_quantity > '10'::numeric) [rows: 600128800 -> 479262800]
GPU-Direct SQL: enabled (GPU-0)
KVars-Slot: <slot=0, type='numeric', expr='lo_quantity'>, <slot=1, type='bpchar', expr='lo_shipmode'>, <slot=2, type='bpchar', expr='lo_shipmode'>, <slot=3, type='float8', expr='lo_quantity'>
KVecs-Buffer: nbytes: 83968, ndims: 2, items=[kvec0=<0x0000-dfff, type='numeric', expr='lo_quantity'>, kvec1=<0xe000-147ff, type='bpchar', expr='lo_shipmode'>]
LoadVars OpCode: {Packed items[0]={LoadVars(depth=0): kvars=[<slot=0, type='numeric' resno=9(lo_quantity)>, <slot=1, type='bpchar' resno=17(lo_shipmode)>]}}
MoveVars OpCode: {Packed items[0]={MoveVars(depth=0): items=[<slot=0, offset=0x0000-dfff, type='numeric', expr='lo_quantity'>, <slot=1, offset=0xe000-147ff, type='bpchar', expr='lo_shipmode'>]}}}
Scan Quals OpCode: {Func(bool)::numeric_gt args=[{Var(numeric): slot=0, expr='lo_quantity'}, {Const(numeric): value='10'}]}
Group-By KeyHash OpCode: {HashValue arg={SaveExpr: <slot=1, type='bpchar'> arg={Var(bpchar): kvec=0xe000-14800, expr='lo_shipmode'}}}
Group-By KeyLoad OpCode: {LoadVars(depth=-2): kvars=[<slot=2, type='bpchar' resno=3(lo_shipmode)>]}
Group-By KeyComp OpCode: {Func(bool)::bpchareq args=[{Var(bpchar): slot=1, expr='lo_shipmode'}, {Var(bpchar): slot=2, expr='lo_shipmode'}]}
Partial Aggregation OpCode: {AggFuncs <nrows[*], psum::fp[slot=3, expr='lo_quantity'], vref[slot=1, expr='lo_shipmode']> args=[{SaveExpr: <slot=3, type='float8'> arg={Func(float8)::float8 arg={Var(numeric): kvec=0x0000-e000, expr='lo_quantity'}}}, {SaveExpr: <slot=1, type='bpchar'> arg={Var(bpchar): kvec=0xe000-14800, expr='lo_shipmode'}}]}
Partial Function BufSz: 24
(18 rows)
現在はまだ実装されていませんが、この疑似コードは、将来的にCSD(Computational Storage Drive)やDPU(Data Processing Unit)でSQL処理をオフロードするために設計されています。
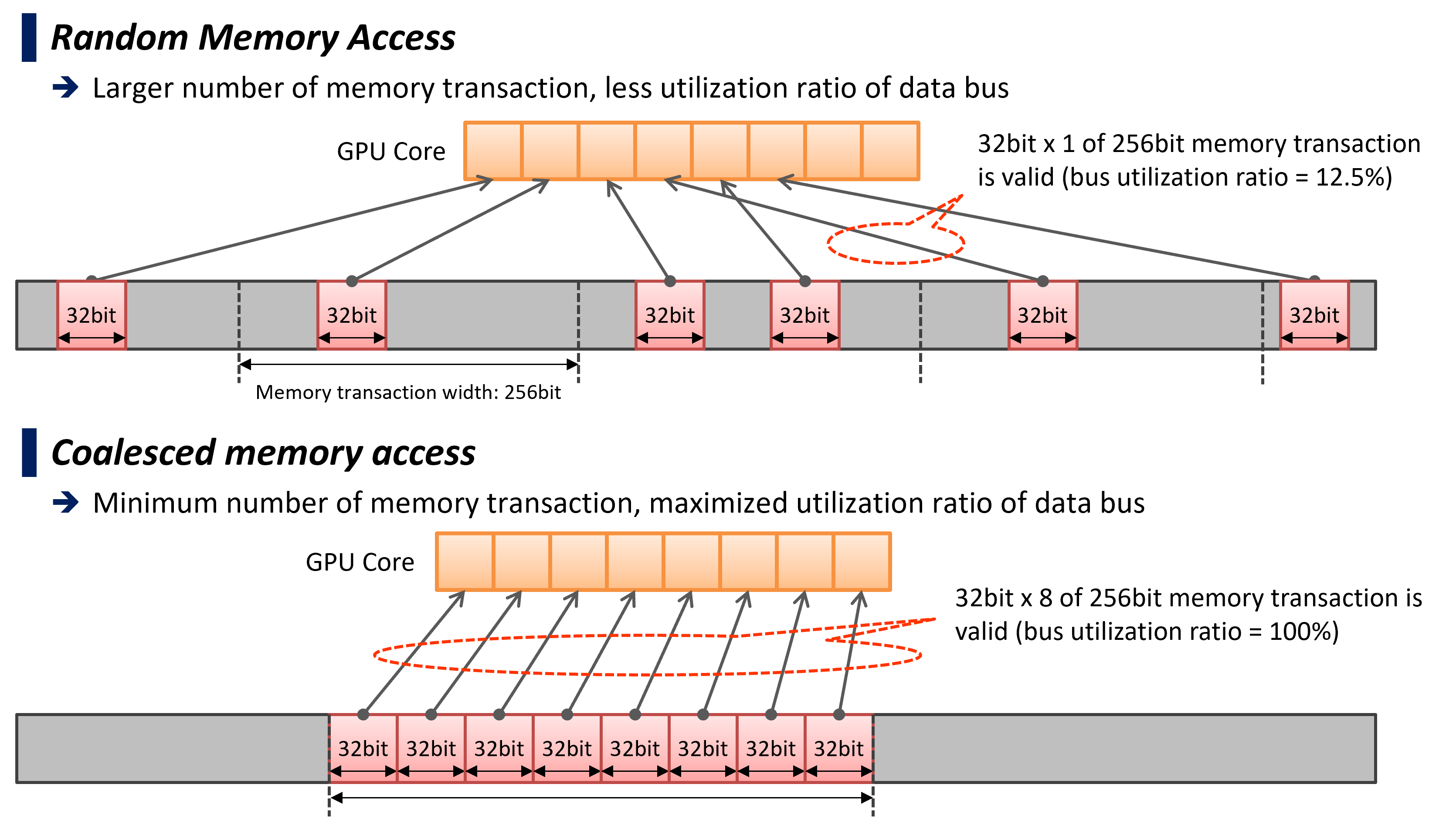
データレイアウトの改善
CPUと比較して、GPUは広帯域なメモリを持っていますが、この性能を引き出すには近傍のメモリ領域を同じタイミングでアクセスするCoalesced Memory Accessの条件を満たす必要があります。
v5.0ではGPUデバイスコードにおけるPostgreSQLデータ型のレイアウトが改良され、Coalesced Memory Accessに適した形式となりました。 PostgreSQLのデータ型をそのまま利用した場合、あるタイミングで参照されるフィールドは飛び飛びの位置を取る事になり、DRAMからの読出し帯域を有効に活用できません。これをフィールド毎に複数個まとめて配置する事で、隣接コアが隣接領域からデータを読み出せるようになり、Coalesced Memory Accessの条件を満たしやすくなります。
この改良は、極めて高性能なメモリ帯域を持つハイエンドGPU製品だけでなく、ミドルエンド級のGPUでも十分な実行性能を引き出すためのものです。
Arrow_Fdwの統計情報サポート
Pg2Arrowでmin/max統計情報付きのApache Arrowファイルを生成する事ができるようになりました。
Pg2Arrowの新たなオプション--stat=COLUMN_NAMEは、RecordBatch単位で指定した列の最大値/最小値を記録しておき、それをApache ArrowのCustom-Metadataメカニズムを利用してフッタに埋め込みます。
Arrow_Fdwを介してApache Arrowファイルを読み出す際、上記のmin/max統計情報を利用した範囲インデックススキャンを実行します。
例えば、Arrow_Fdw外部テーブルに対する検索条件が以下のようなものであった場合、
WHERE ymd BETERRN '2020-01-01'::date AND '2021-12-31'::date
ymdフィールドの最大値が'2020-01-01'::date未満であるRecord Batchや、
ymdフィールドの最小値が'2021-12-31::date`より大きなRecord Batchは、
検索条件にマッチしない事が明らかであるため、Arrow_FdwはこのRecord Batchを読み飛ばします。
これにより、例えばログデータのタイムスタンプなど、近しい値を持つレコードが近傍に集まっているパターンのデータセットにおいては、範囲インデックスを用いた絞込みと同等の性能が得られます。
その他の変更点
- PostgreSQL v14 以前のバージョンはサポートされなくなりました。v15以降へのバージョンアップをお願いします。
- Partition-wise GpuJoin機能に関しては、開発スケジュール上の理由により、v5.0では無効化されています。将来のバージョンで再び実装される予定です。