Fluentd連携
本章では、Apache Arrowデータ形式を介したFluentdとの連携と、IoT/M2Mログデータの効率的な取り込みについて説明します。
概要
IoT/M2Mとよばれる技術領域においては、PCやサーバだけでなく、携帯電話や自動車、各種センサーなどのデバイスが生成した大量のログデータを蓄積し、これを分析するためのソフトウェアが数多く開発されています。大量のデバイスが時々刻々と生成するデータは非常に大きなサイズになりがちで、これを実用的な時間内に処理するには、特別な工夫が必要となるからです。
PG-Stromの各種機能は、こういった規模のログデータを高速に処理するために設計・実装されています。
しかし一方で、こうした規模のデータの検索・集計が可能な状態にするためにデータを移送し、データベースに取り込むには時間がかかりがちです。
そこで、PG-StromにはFluentd向けにApache Arrow形式でログデータを出力するfluent-plugin-arrow-fileモジュールを同梱し、ログデータのインポートという問題に対処を試みています。
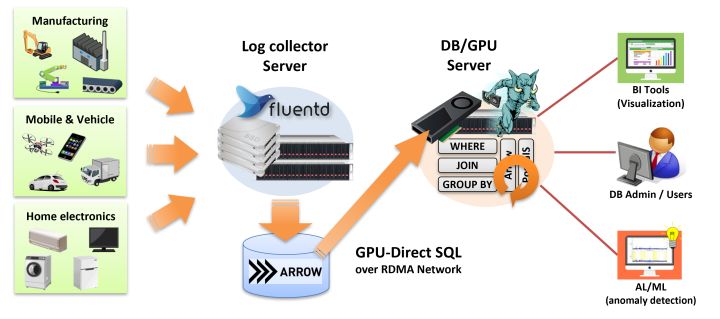
Fluentdは古橋貞之氏によって開発されたログ収集ツールで、SyslogのようなサーバログからIoT/M2M機器のデバイスログに至るまで、多種多様なログデータを集積・保存するために事実上のスタンダードとして利用されているソフトウェアです。 Rubyで記述されたプラグインの追加により、ログデータの入出力や加工を自在にカスタマイズする事が可能で、2022年現在、800種類を越えるプラグインが公式Webサイトで紹介されています。
PG-Stromが取り扱うことのできるデータ形式は、PostgreSQL Heap形式(トランザクショナル行データ)とApache Arrow形式(構造化列データ)の2種類ですが、IoT/M2M領域で想定されるような、時々刻々と大量のデータが発生するようなワークロードに対しては、Apache Arrow形式を用いた方が合理的です。
arrow-file プラグイン
以下では、Fluentdが収集したログデータをApache Arrow形式ファイルとして出力し、これをPG-Stromで参照するというアプローチについて説明します。
また、Fluentdのパッケージには、Treasure Data社の提供する安定版fluentdを使用するものとします。
PG-Stromに同梱のFluentd向けOutputプラグインのfluent-plugin-arrow-fileモジュールを利用すると、Fluentdが収集したログデータを、指定したスキーマ構造を持つApache Arrow形式ファイルとして書き出すことができます。PG-StromのArrow_Fdw機能を使用すればこのApache Arrow形式ファイルを外部テーブルとして参照する事ができ、また保存先のストレージが適切に設定されていれば、GPU-Direct SQLを用いた高速な読み出しも可能です。
この方法には以下のメリットがあります。 - Fluentd が出力したデータをそのままPG-Stromで読み出せるため、改めてDBへデータをインポートする必要がない。 - 列データ形式であるため、検索・集計処理に伴うデータの読み出し(I/O負荷)を必要最小限に抑える事ができる。 - 古くなったログデータのアーカイブも、OS上のファイル移動のみで完了できる。
一方で、Apache Arrow形式で性能上のメリットを得るには、Record Batchのサイズをある程度大きくしなければならないため、ログの発生頻度が小さく、一定サイズのログが溜まるまでに時間のかかる場合には、PostgreSQLのテーブルに出力させるなど、別の方法を試した方がよりリアルタイムに近いログ分析が可能でしょう。
内部構造
Fluentdのプラグインにはいくつかカテゴリがあり、外部からログを受け取るInputプラグイン、ログを成形するParserプラグイン、受信したログを一時的に蓄積するBufferプラグイン、ログを出力するOutputプラグイン、などの種類があります。
arrow-fileはOutputプラグインの一つですが、これはBufferプラグインから渡されたログデータの固まり(chunk)を、コンフィグで指定されたスキーマ構造を持つApache Arrow形式で書き出す役割を担っています。
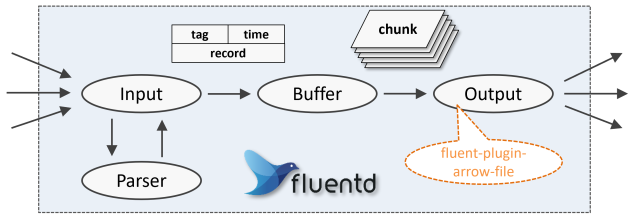
Input/Parserプラグインの役割は、外部から受け取ったログを共通の形式に変換し、BufferプラグインやOutputプラグインが入力データの形式を意識することなく扱えるようにすることです。
これは内部的には、ログの振り分けに利用することのできる識別子のtag、ログのタイムスタンプtime、および生ログを成形した連想配列であるrecordの組です。
arrow-fileプラグインは、tag、timeの各フィールドと、record連想配列の各要素(一部を省略することも可能)を列として持つApache Arrow形式ファイルへの書き出しを行います。
そのため、出力先のファイル名とスキーマ定義情報(連想配列の要素と列/型のマッピング)は必須の設定パラメータです。
インストール
使用しているLinuxディストリビューション用のfluent-packageパッケージをインストールします。
詳しくはこちらを参照してください。
$ curl -fsSL https://fluentd.cdn.cncf.io/sh/install-redhat-fluent-package6-lts.sh | sh
次に、PG-Stromのソースコードをダウンロードし、fluentd ディレクトリ以下の物件をビルドします。
$ git clone https://github.com/heterodb/pg-strom.git
$ cd pg-strom/fluentd
$ make gem
$ sudo make install
Fluentdのプラグインがインストールされている事を確認するため、以下のコマンドを実行します。
$ /opt/fluent/bin/fluent-gem list | grep arrow
fluent-plugin-arrow-file (0.5)
設定
前述の通り、arrow-fileプラグインを動作させるには、出力先のパス名とスキーマ定義を設定することが最低限必要です。
FluentdのWriteプラグインの構造上、arrow-fileプラグインは、Bufferプラグインから渡されたデータチャンクを1個のRecord Batchとしてファイルに書き込みます(Parquet形式ではRow Groupと呼びますが、ほぼ同じ概念です)。 検索・集計処理を行う際には、ある程度大きなサイズのRecord Batchを作っておいた方が処理性能を引き出しやすいですが、GPUメモリに収まりきらないようなサイズはPG-Strom利用の観点からは望ましくありません。 arrow-fileプラグインは、Bufferプラグインから渡されるデータチャンクごとにRecord Batchを作成するため、Bufferプラグイン側のバッファサイズはこれに準じた設定を行うべきです。デフォルトでは 256MB のバッファサイズを取るように設定されています。必要に応じて256MB~2GB程度のバッファサイズを設定すべきでしょう。
また、以前のバージョンのarrow-fileプラグインは、Bufferプラグインからデータチャンクが渡されるたびに、既に書き込まれたArrowファイルにRecord Batchを追記していましたが、v0.5以降では、1ファイル=1Record Batch (1Row Group)という構造になっています。 これは、libarrowやlibparquetが追記をサポートしていない事と、生成されたファイルを使用する際に排他処理が必須になってしまう事が理由です。
arrow-fileプラグインの設定パラメータは以下の通りです。
path[type:String] (必須パラメータ)- arrow-fileプラグインがログを出力するファイル名を指定します。
- このパラメータは必須で、以下の書式文字を含める事ができます。
| 書式 | 説明 |
|---|---|
%Y |
現在の年を西暦4桁で表現した数値で置き換えます。 |
%y |
現在の年の西暦下2桁で表現した数値で置き換えます。 |
%m |
現在の月を 01~12 で表した2桁の数値で置き換えます。 |
%d |
現在の日を 01~31 で表した2桁の数値で置き換えます。 |
%H |
現在時刻の時を00~23で表した2桁の数値で置き換えます。 |
%M |
現在時刻の分を00~59で表した2桁の数値で置き換えます。 |
%S |
現在時刻の秒を00~59で表した2桁の数値で置き換えます。 |
%p |
現在の Fluentd プロセスのPIDで置き換えます。 |
書式文字列はデータチャンクを書き出すタイミングで評価され、その名前を持つApache Arrow形式ファイル(またはApache Parquet形式ファイル)を新規作成して、Record Batch(またはRow Group)を1個持つファイルを書き出します。 同名のファイルが存在する場合、ファイルの末尾にシーケンス番号を付与するなどして、別名でのファイル作成を試みます。
例)path /tmp/arrow_logs/my_logs_%y%m%d.%p.log
schema_defs[type:String] (必須パラメータ)fluent-plugin-arrow-fileがログデータを出力する際の、Apache Arrow形式ファイルのスキーマ定義を指定します。- このパラメータは必須で、以下の形式で記述された文字列によりスキーマ構造を定義します。
schema_defs := column_def1[,column_def2 ...]column_def := <column_name>=<column_type>[;<column_attrs>]<column_name>は列の名前です。Fluentdからarrow-fileに渡される連想配列のキー値と一致している必要があります。<column_type>は列のデータ型です。以下の表を参照してください。<column_attrs>は列の付加属性です。現時点では以下の属性のみがサポートされています。stat_enabled... Arrow形式において、列の統計情報を収集し、Record Batchごとの最大値/最小値をmax_values=...およびmin_values=...カスタムメタデータとして埋め込みます。Parquet形式では無視されます。stat_disabled... Parquet形式はデフォルトで列ごとの統計情報を採取しますが、それを無効化します。Apache形式では無視されます。- 圧縮オプション ... 列単位の圧縮アルゴリズムを指定する事ができます。選択可能なアルゴリズムは
snappy、gzip、brotli、zstd、lz4、lzo、bz2、none(無圧縮)のいずれかです。
(例)schema_defs "ts=Timestamp;stat_enabled,dev_id=Uint32,temperature=Float32;bz2,humidity=Float32"
arrow-fileプラグインのサポートするデータ型
| データ型 | 説明 |
|---|---|
Int8 Int16 Int32 Int64 |
符号付き整数型で、それぞれ指定したビット幅を持ちます。 |
Uint8 Uint16 Uint32 Uint64 |
符号なし整数型で、それぞれ指定したビット幅を持ちます。 |
Float16 Float32 Float64 |
浮動小数点型で、それぞれ半精度(16bit)、単精度(32bit)、倍精度(64bit)の幅を持ちます。 |
Decimal Decimal128 |
128bit固定小数点型です。256bit固定小数点型は現在未サポートです。 |
Timestamp Timestamp[sec] Timestamp[ms] Timestamp[us] Timestamp[ns] |
タイムスタンプ型です。精度を指定することができ、省略した場合は暗黙に[us]を付加したものとして扱われます。 |
Time Time[sec] Time[ms] Time[us] Time[ns] |
時刻型です。精度を指定することができ、省略した場合は暗黙に[sec]を付加したものとして扱われます。 |
Date Date[Day] Date[ms] |
日付型です。精度を指定することができ、省略した場合は暗黙に[day]を付加したものとして扱われます。 |
Utf8 |
文字列型です。 |
Ipaddr4 |
IPv4アドレス型です。実際にはbyteWidth=4であるFixedSizeBinary型に、pg_type=pg_catalog.inetというカスタムメタデータを付与します。 |
Ipaddr6 |
IPv6アドレス型です。実際にはbyteWidth=16であるFixedSizeBinary型に、pg_type=pg_catalog.inetというカスタムメタデータを付与します。 |
ts_column[type:String/ default: なし]- 指定した列の値を(
record連想配列からではなく)Fluentdから渡されたログのタイムスタンプ値より取得します。 - 通常、このオプションで指定する列は
Timestampなどの日付時刻型を持っており、またstat_enabled属性と併用することで検索処理の高速化が期待できます。 tag_column[type:String/ default: なし]- 指定した列の値を(
record連想配列からではなく)Fluentdから渡されたログのタグ値より取得します。 - 通常、このオプションで指定する列は
Utf8などの文字列型を持っています。 format[type:String/ default:arrow]fluent-plugin-arrow-fileが出力するファイル形式を設定します。arrowを指定するとApache Arrow形式に、parquetを指定するとApache Parquet形式となります。
使用例
簡単な例として、ローカルのApache Httpdサーバのログを監視し、それをフィールド毎にパースしてApache Arrow形式ファイルに書き込みます。
<source>で/var/log/httpd/access_logをデータソースとして指定しているほか、apache2のParseプラグインを用いて、host, user, time, method, path, code, size, referer, agentの各フィールドを切り出しています。
これらはarrow-fileプラグインに連想配列として渡され、<match>内のschema_defsには、これらのフィールドに対応するApache Arrowファイルの列定義を記述しています。
また、ここでは簡単な使用例を示すことが目的ですので、<buffer>タグでチャンクサイズを最大4MB / 200行に縮小し、最大でも10秒でOutputプラグインに渡すよう設定しています。
/etc/fluent/fluentd.confの設定例
<source>
@type tail
path /var/log/httpd/access_log
pos_file /var/log/fluent/httpd_access.pos
tag httpd
format apache2
<parse>
@type apache2
expression /^(?<host>[^ ]*) [^ ]* (?<user>[^ ]*) \[(?<time>[^\]]*)\] "(?<method>\S+)(?: +(?<path>(?:[^\"]|\\.)*?)(?: +\S*)?)?" (?<code>[^ ]*) (?<size>[^ ]*)(?: "(?<referer>(?:[^\"]|\\.)*)" "(?<agent>(?:[^\"]|\\.)*)")?$/
time_format %d/%b/%Y:%H:%M:%S %z
</parse>
</source>
<match httpd>
@type arrow_file
path /tmp/mytest%Y%m%d.%p.arrow
schema_defs "ts=Timestamp[sec],host=Utf8,method=Utf8,path=Utf8,code=Int32,size=Int32,referer=Utf8,agent=Utf8"
ts_column "ts"
<buffer>
flush_interval 10s
chunk_limit_size 4MB
chunk_limit_records 200
</buffer>
</match>
fluentdを起動します。
$ sudo systemctl start fluentd
以下のように、Apache Httpdのログが path で設定した /tmp/mytest%Y%m%d.%p.arrow が展開された先である /tmp/mytest20220124.3206341.arrow に書き出されています。
$ arrow2csv /tmp/mytest20220124.3206341.arrow --head --offset 300 --limit 10
"ts","host","method","path","code","size","referer","agent"
"2022-01-24 06:13:42","192.168.77.95","GET","/docs/ja/js/theme_extra.js",200,195,"http://buri/docs/ja/fluentd/","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36"
"2022-01-24 06:13:42","192.168.77.95","GET","/docs/ja/js/theme.js",200,4401,"http://buri/docs/ja/fluentd/","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36"
"2022-01-24 06:13:42","192.168.77.95","GET","/docs/ja/img/fluentd_overview.png",200,121459,"http://buri/docs/ja/fluentd/","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36"
"2022-01-24 06:13:42","192.168.77.95","GET","/docs/ja/search/main.js",200,3027,"http://buri/docs/ja/fluentd/","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36"
"2022-01-24 06:13:42","192.168.77.95","GET","/docs/ja/fonts/Lato/lato-regular.woff2",200,182708,"http://buri/docs/ja/css/theme.css","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36"
"2022-01-24 06:13:42","192.168.77.95","GET","/docs/ja/fonts/fontawesome-webfont.woff2?v=4.7.0",200,77160,"http://buri/docs/ja/css/theme.css","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36"
"2022-01-24 06:13:42","192.168.77.95","GET","/docs/ja/fonts/RobotoSlab/roboto-slab-v7-bold.woff2",200,67312,"http://buri/docs/ja/css/theme.css","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36"
"2022-01-24 06:13:42","192.168.77.95","GET","/docs/ja/fonts/Lato/lato-bold.woff2",200,184912,"http://buri/docs/ja/css/theme.css","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36"
"2022-01-24 06:13:43","192.168.77.95","GET","/docs/ja/search/worker.js",200,3724,"http://buri/docs/ja/fluentd/","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36"
"2022-01-24 06:13:43","192.168.77.95","GET","/docs/ja/img/favicon.ico",200,1150,"http://buri/docs/ja/fluentd/","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36"
これを PG-Strom のArrow_Fdwを用いてPostgreSQLにマッピングしてみます。
postgres=# IMPORT FOREIGN SCHEMA mytest
FROM SERVER arrow_fdw INTO public
OPTIONS (file '/tmp/mytest20220124.3206341.arrow');
IMPORT FOREIGN SCHEMA
postgres=# SELECT ts, host, path FROM mytest WHERE code = 404;
ts | host | path
---------------------+---------------+----------------------
2022-01-24 12:02:06 | 192.168.77.73 | /~kaigai/ja/fluentd/
(1 row)
postgres=# EXPLAIN SELECT ts, host, path FROM mytest WHERE code = 404;
QUERY PLAN
------------------------------------------------------------------------------
Custom Scan (GpuScan) on mytest (cost=4026.12..4026.12 rows=3 width=72)
GPU Filter: (code = 404)
referenced: ts, host, path, code
files0: /tmp/mytest20220124.3206341.arrow (read: 128.00KB, size: 133.94KB)
(4 rows)
生成された Apache Arrow ファイルを外部テーブルとしてマッピングし、これをSQLから参照しています。
Fluentd側で成形されたログの各フィールドを参照する検索条件を与える事ができます。 上記の例では、HTTPステータスコード404のログを検索し、1件がヒットしています。