PG-Strom v5.0 Release
Overview
Major changes in PG-Strom v5.0 are as follows:
- The code base has been re-designed entirely with various improvement.
- Process model was revised to multi-threaded background worker (PG-Strom GPU Service) from multi-process model. It reduced GPU resource consumption and overhead of task-switching.
- GPU device code dynamically generated using CUDA C++ was replaced by the pseudo kernel code. It eliminates just-in-time compilation using NVRTC, and improved the first response time. This is also a groundwork for the future support of CSD(Computational Storage Drive) and DPU(Data Processing Unit).
- GPU-Cache is now deployed on CUDA managed memory that allows overcommit of GPU device memory.
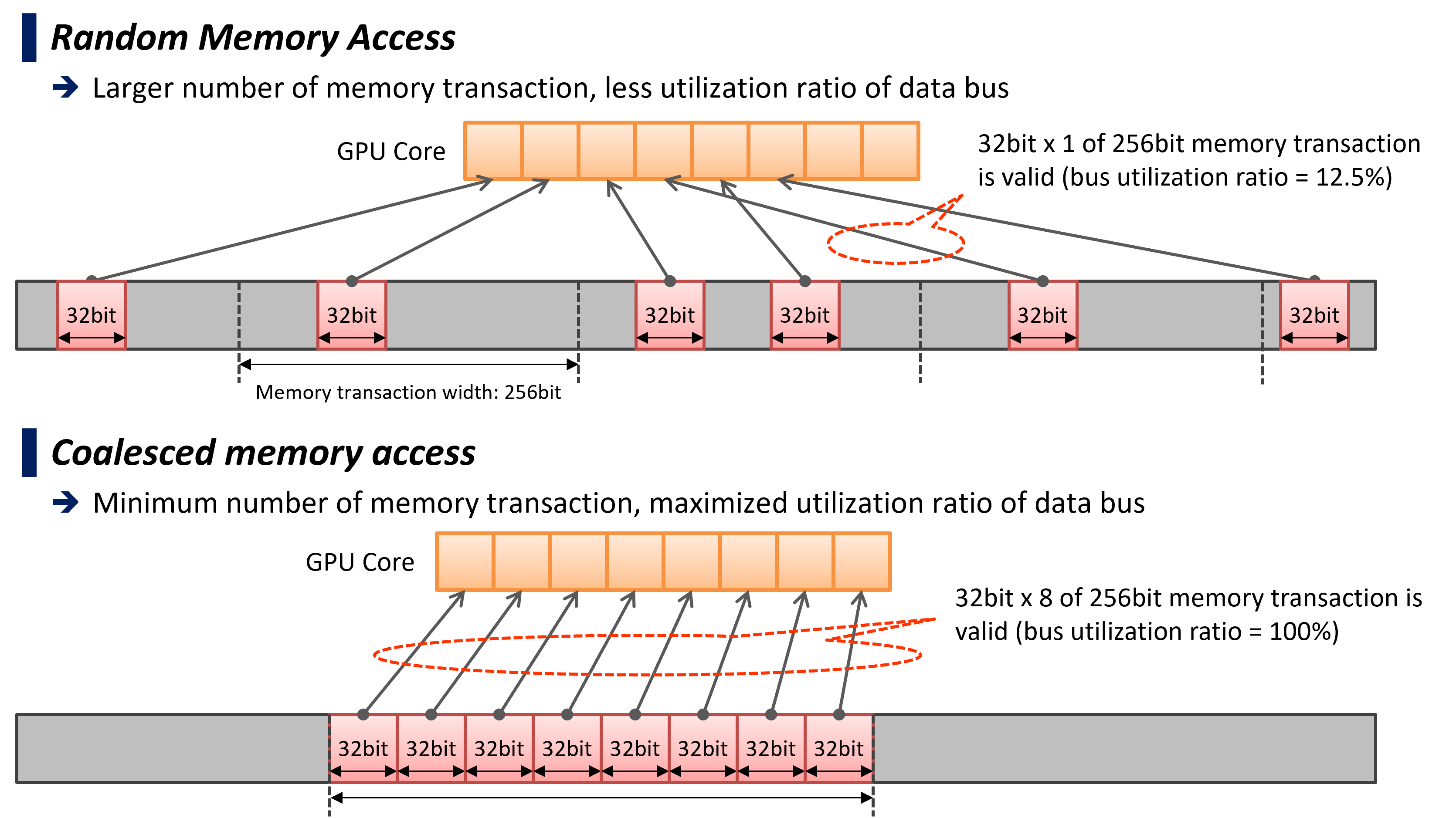
- Data layout of PostgreSQL data types were revised to adjust Coalesced Memory Access.
- GpuPreAgg replaced entire GROUP BY implementation, then improved whole performance.
- GpuJoin extract tuples only once regardless of the depth of Join.
- Arrow_Fdw and Pg2Arrow supports min/max statistics of arrow files.
- Two arrow tools were added: Pca2Arrow captures network packets, and arrow2csv dumps arrow files in CSV format.
Prerequisites
- PostgreSQL v15.x, v16.x
- CUDA Toolkit 12.2 or later
- Linux distributions supported by CUDA Toolkit
- Intel x86 64bit architecture (x86_64)
- NVIDIA GPU CC 6.0 or later (Pascal at least; Volta or newer is recommended)
New Process Model
In v5.0, the multi-threaded background worker process (PG-Strom GPU Service) coordinates GPU resources and task executions, and individual PostgreSQL backend processes send requests to and receive results from the GPU service over IPC.
Before the v3.x series, each PostgreSQL backend controls GPU devices individually. This design helps software debugging by easy identification of the problematic code when software quality of CUDA and PG-Strom were not sufficient, however, it extremely consumed GPU resources according to increase of database sessions, and was not recommended software architecture from the standpoint of task-switching.
This design change makes PG-Strom v5.0 more stable towards increase of concurrent database sessions, and improves heavy GPU task's performance.
Pseudo device code
PG-Strom v5.0 now generates its own "pseudo-code" from the supplied SQL, and the GPU device code works as an interpreter to execute this "pseudo-code". Unlike v3.x series, it does not generate CUDA C++ native code no longer.
At first glance, this may appear to be a factor in performance degradation. However, dynamic code generation was originally targeted for only a small part of the code that changes with each query, such as the WHERE clause; most implementations were statically built, and runtime compilation was handled by NVRTC. (approximately 150ms) can now be omitted, contributing to improved response time.
The "pseudo-code" is a set of low-level commands, can be displayed in EXPLAIN VERBOSE. For example, the query below contains the expression lo_quantity > 10 in the WHERE clause. This operation is defined as Scan Quals OpCode to call the numeric_gt function which compares the magnitude relationship between the lo_quantity column and the constant 10.
postgres=# explain verbose select count(*), sum(lo_quantity), lo_shipmode from lineorder where lo_quantity > 10 group by lo_shipmode;
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
HashAggregate (cost=3242387.01..3242387.10 rows=7 width=51)
Output: pgstrom.fcount((pgstrom.nrows())), pgstrom.sum_fp_num((pgstrom.psum((lo_quantity)::double precision))), lo_shipmode
Group Key: lineorder.lo_shipmode
-> Custom Scan (GpuPreAgg) on public.lineorder (cost=3242386.89..3242386.96 rows=7 width=51)
Output: (pgstrom.nrows()), (pgstrom.psum((lo_quantity)::double precision)), lo_shipmode
GPU Projection: pgstrom.nrows(), pgstrom.psum((lo_quantity)::double precision), lo_shipmode
GPU Scan Quals: (lo_quantity > '10'::numeric) [rows: 600128800 -> 479262800]
GPU-Direct SQL: enabled (GPU-0)
KVars-Slot: <slot=0, type='numeric', expr='lo_quantity'>, <slot=1, type='bpchar', expr='lo_shipmode'>, <slot=2, type='bpchar', expr='lo_shipmode'>, <slot=3, type='float8', expr='lo_quantity'>
KVecs-Buffer: nbytes: 83968, ndims: 2, items=[kvec0=<0x0000-dfff, type='numeric', expr='lo_quantity'>, kvec1=<0xe000-147ff, type='bpchar', expr='lo_shipmode'>]
LoadVars OpCode: {Packed items[0]={LoadVars(depth=0): kvars=[<slot=0, type='numeric' resno=9(lo_quantity)>, <slot=1, type='bpchar' resno=17(lo_shipmode)>]}}
MoveVars OpCode: {Packed items[0]={MoveVars(depth=0): items=[<slot=0, offset=0x0000-dfff, type='numeric', expr='lo_quantity'>, <slot=1, offset=0xe000-147ff, type='bpchar', expr='lo_shipmode'>]}}}
Scan Quals OpCode: {Func(bool)::numeric_gt args=[{Var(numeric): slot=0, expr='lo_quantity'}, {Const(numeric): value='10'}]}
Group-By KeyHash OpCode: {HashValue arg={SaveExpr: <slot=1, type='bpchar'> arg={Var(bpchar): kvec=0xe000-14800, expr='lo_shipmode'}}}
Group-By KeyLoad OpCode: {LoadVars(depth=-2): kvars=[<slot=2, type='bpchar' resno=3(lo_shipmode)>]}
Group-By KeyComp OpCode: {Func(bool)::bpchareq args=[{Var(bpchar): slot=1, expr='lo_shipmode'}, {Var(bpchar): slot=2, expr='lo_shipmode'}]}
Partial Aggregation OpCode: {AggFuncs <nrows[*], psum::fp[slot=3, expr='lo_quantity'], vref[slot=1, expr='lo_shipmode']> args=[{SaveExpr: <slot=3, type='float8'> arg={Func(float8)::float8 arg={Var(numeric): kvec=0x0000-e000, expr='lo_quantity'}}}, {SaveExpr: <slot=1, type='bpchar'> arg={Var(bpchar): kvec=0xe000-14800, expr='lo_shipmode'}}]}
Partial Function BufSz: 24
(18 rows)
Although not currently implemented, this pseudo-code is also designed to offload SQL processing to a CSD (Computational Storage Drive) or DPU (Data Processing Unit) in the future.
Improvement of data layout
GPU has a wider memory bandwidth than CPU, but in order to take advantage of this performance, it is necessary to satisfy the condition of coalesced memory access, which accesses nearby memory areas at the same time.
In v5.0, the layout of PostgreSQL data types in GPU device code has been improved to make them more suitable for Coalesced Memory Access. If we would use the PostgreSQL data type as is, fields that are referenced at certain times will be placed in discrete positions, making it impossible to effectively utilize the read bandwidth from DRAM. By arranging multiple of these for each field, adjacent cores can read data from adjacent areas, making it easier to satisfy the conditions of Coalesced Memory Access.
This improvement is aimed at bringing out sufficient execution performance not only for high-end GPU products with extremely high performance memory bandwidth, but also for mid-end GPUs.
Arrow_Fdw supports min/max statistics
Pg2Arrow can now generate Apache Arrow files with min/max statistics.
Its new option --stat=COLUMN_NAME records the maximum/minimum value of the specified column for each RecordBatch and embeds it in the footer using Apache Arrow's Custom-Metadata mechanism.
When reading an Apache Arrow file using Arrow_Fdw, perform like a range index scan using the above min/max statistics.
For example, if the WHERE-clause for the Arrow_Fdw foreign table is as follows:
WHERE ymd BETERRN '2020-01-01'::date AND '2021-12-31'::date
Arrow_Fdw will skip the record-batch where the maximum value of the ymd field is less than '2020-01-01'::date, or the record-batch where the minimum value of ymd field is greater than '2021-12-31::date`, because it is obvious that it does not match the search conditions.
As a result, performance equivalent to narrowing down using a range index can be obtained for datasets with patterns in which records with similar values are clustered nearby, such as log data timestamps.
Other changes
- PG-Strom v5.0 stopped support of PostgreSQL v14 or older. Plan version up v15 or later.
- Due to development schedule reason, v5.0 disables partition-wise GpuJoin. It shall be re-implemented at the near future version.