Apache Arrow (Columnar Store)
Overview
PostgreSQL tables internally consist of 8KB blocks1, and block contains tuples which is a data structure of all the attributes and metadata per row. It collocates date of a row closely, so it works effectively for INSERT/UPDATE-major workloads, but not suitable for summarizing or analytics of mass-data.
It is not usual to reference all the columns in a table on mass-data processing, and we tend to reference a part of columns in most cases. In this case, the storage I/O bandwidth consumed by unreferenced columns are waste, however, we have no easy way to fetch only particular columns referenced from the row-oriented data structure.
In case of column oriented data structure, in an opposite manner, it has extreme disadvantage on INSERT/UPDATE-major workloads, however, it can pull out maximum performance of storage I/O on mass-data processing workloads because it can loads only referenced columns. From the standpoint of processor efficiency also, column-oriented data structure looks like a flat array that pulls out maximum bandwidth of memory subsystem for GPU, by special memory access pattern called Coalesced Memory Access.
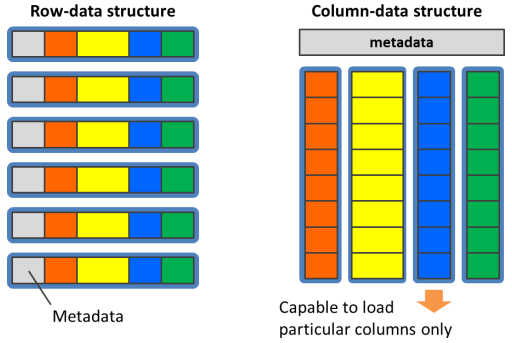
What is Apache Arrow?
Apache Arrow is a data format of structured data to save in columnar-form and to exchange other applications. Some applications for big-data processing support the format, and it is easy for self-developed applications to use Apache Arrow format since they provides libraries for major programming languages like C,C++ or Python.
![]()
Apache Arrow format file internally contains Schema portion to define data structure, and one or more RecordBatch to save columnar-data based on the schema definition. For data types, it supports integers, strint (variable-length), date/time types and so on. Indivisual columnar data has its internal representation according to the data types.
Data representation in Apache Arrow is not identical with the representation in PostgreSQL. For example, epoch of timestamp in Arrow is 1970-01-01 and it supports multiple precision. In contrast, epoch of timestamp in PostgreSQL is 2001-01-01 and it has microseconds accuracy.
Arrow_Fdw allows to read Apache Arrow files on PostgreSQL using foreign table mechanism. If an Arrow file contains 8 of record batches that has million items for each column data, for example, we can access 8 million rows on the Arrow files through the foreign table.
Operations
Creation of foreign tables
Usually it takes the 3 steps below to create a foreign table.
- Define a foreign-data-wrapper using
CREATE FOREIGN DATA WRAPPERcommand - Define a foreign server using
CREATE SERVERcommand - Define a foreign table using
CREATE FOREIGN TABLEcommand
The first 2 steps above are included in the CREATE EXTENSION pg_strom command. All you need to run individually is CREATE FOREIGN TABLE command last.
CREATE FOREIGN TABLE flogdata (
ts timestamp,
sensor_id int,
signal1 smallint,
signal2 smallint,
signal3 smallint,
signal4 smallint,
) SERVER arrow_fdw
OPTIONS (file '/path/to/logdata.arrow');
Data type of columns specified by the CREATE FOREIGN TABLE command must be matched to schema definition of the Arrow files to be mapped.
Arrow_Fdw also supports a useful manner using IMPORT FOREIGN SCHEMA statement. It automatically generates a foreign table definition using schema definition of the Arrow files. It specifies the foreign table name, schema name to import, and path name of the Arrow files using OPTION-clause. Schema definition of Arrow files contains data types and optional column name for each column. It declares a new foreign table using these information.
IMPORT FOREIGN SCHEMA flogdata
FROM SERVER arrow_fdw
INTO public
OPTIONS (file '/path/to/logdata.arrow');
Foreign table options
Arrow_Fdw supports the options below.
Foreign Table Options
file=PATHNAME- It maps an Arrow file specified on the foreign table.
files=PATHNAME1[,PATHNAME2...]- It maps multiple Arrow files specified by comma (,) separated files list on the foreign table.
dir=DIRNAME- It maps all the Arrow files in the directory specified on the foreign table.
suffix=SUFFIXWhendiroption is given, it maps only files with the specified suffix, like.arrow` for example.parallel_workers=N_WORKERS- It tells the number of workers that should be used to assist a parallel scan of this foreign table; equivalent to
parallel_workersstorage parameter at normal tables. pattern=PATTERN- Maps only files specified by the
file,files, ordiroption that match thePATTERN, including wildcards, to the foreign table. - The following wildcards can be used:
-
?... matches any 1 character.
-
*... matches any string of 0 or more characters.
-
${KEY}... matches any string of 0 or more characters.
-
@{KEY}... matches any numeric string of 0 or more characters.
- An interesting use of this option is to refer to a portion of a file name matched by the wildcard
${KEY}or@{KEY}as a virtual column. For more information, see the '''Arrow_Fdw virtual column''' section below.
Foreign Column Options
field=FIELD- It specifies the field name of the Arrow file to map to that column.
- In the default, Arrow_Fdw maps the first occurrence of a field that has the same column name as this foreign table's column name.
virtual=KEY- It configures the column is a virtual column.
KEYspecifies the wildcard key name in the pattern specified by thepatternoption of the foreign table option. - A virtual column allows to refer to the part of the file name pattern that matches
KEYin a query. virtual_metadata=KEY- It specifies that the column is a virtual column.
KEYspecifies a KEY-VALUE pair embedded in the CustomMetadata field of the Arrow file. If the specified KEY-VALUE pair is not found, the column returns a NULL value. - There are two types of CustomMetadata in Arrow files: embedded in the schema (corresponding to a PostgreSQL table) and embedded in the field (corresponding to a PostgreSQL column).
- For example, you can reference CustomMetadata embedded in a field by writing the field name separated by the
.character before the KEY value, such aslo_orderdate.max_values. If there is no field name, it will be treated as a KEY-VALUE pair embedded in the schema. virtual_metadata_split=KEY- It specifies that the column is a virtual column.
KEYspecifies the KEY-VALUE pair embedded in the CustomMetadata field of the Arrow file. If the specified KEY-VALUE pair is not found, this column returns a NULL value. - The difference from
virtual_metadatais that the values of the CustomMetadata field are separated by a delimiter(,) and applied to each Record Batch in order from the beginning. For example, if the specified CustomMetadata value isTokyo,Osaka,Kyoto,Yokohama, the row read from RecordBatch-0 will display'Tokyo', the row read from RecordBatch-1 will display'Osaka', and the row read from RecordBatch-2 will display'Osaka'as the value of this virtual column.
Data type mapping
Arrow data types are mapped on PostgreSQL data types as follows.
Int- mapped to either of
int1,int2,int4orint8according to thebitWidthattribute. is_signedattribute shall be ignored.int1is an enhanced data type by PG-Strom.FloatingPoint- mapped to either of
float2,float4orfloat8according to theprecisionattribute. float2is an enhanced data type by PG-Strom.Utf8,LargeUtf8- mapped to
textdata type Binary,LargeBinary- mapped to
byteadata type Decimal- mapped to
numericdata type Date- mapped to
datedata type; to be adjusted as if it hasunit=Dayprecision. Time- mapped to
timedata type; to be adjusted as if it hasunit=MicroSecondprecision. Timestamp- mapped to
timestampdata type; to be adjusted as if it hasunit=MicroSecondprecision. Interval- mapped to
intervaldata type. List,LargeList- mapped to 1-dimensional array of the element data type.
Struct- mapped to compatible composite data type; that shall be defined preliminary.
FixedSizeBinary- mapped to
char(n)data type according to thebyteWidthattribute. - If
pg_type=TYPENAMEis configured, PG-Strom may assign the configured data type. Right now,inetandmacaddrare supported. Union,Map,Duration- Right now, PG-Strom cannot map these Arrow data types onto any of PostgreSQL data types.
How to read EXPLAIN
EXPLAIN command show us information about Arrow files reading.
The example below is an output of query execution plan that includes f_lineorder foreign table that mapps an Arrow file of 503GB.
=# EXPLAIN
SELECT sum(lo_extendedprice*lo_discount) as revenue
FROM f_lineorder,date1
WHERE lo_orderdate = d_datekey
AND d_year = 1993
AND lo_discount between 1 and 3
AND lo_quantity < 25;
QUERY PLAN
--------------------------------------------------------------------------------
Aggregate (cost=14535261.08..14535261.09 rows=1 width=8)
-> Custom Scan (GpuPreAgg) on f_lineorder (cost=14535261.06..14535261.07 rows=1 width=32)
GPU Projection: pgstrom.psum(((f_lineorder.lo_extendedprice * f_lineorder.lo_discount))::bigint)
GPU Scan Quals: ((f_lineorder.lo_discount >= 1) AND (f_lineorder.lo_discount <= 3) AND (f_lineorder.lo_quantity < 25)) [rows: 5999990000 -> 9999983]
GPU Join Quals [1]: (f_lineorder.lo_orderdate = date1.d_datekey) ... [nrows: 9999983 -> 1428010]
GPU Outer Hash [1]: f_lineorder.lo_orderdate
GPU Inner Hash [1]: date1.d_datekey
referenced: lo_orderdate, lo_quantity, lo_extendedprice, lo_discount
file0: /opt/nvme/f_lineorder_s999.arrow (read: 89.41GB, size: 502.92GB)
GPU-Direct SQL: enabled (GPU-0)
-> Seq Scan on date1 (cost=0.00..78.95 rows=365 width=4)
Filter: (d_year = 1993)
(12 rows)
According to the EXPLAIN output, we can see Custom Scan (GpuPreAgg) scans f_lineorder foreign table. file0 item shows the filename (/opt/nvme/lineorder_s999.arrow) on behalf of the foreign table and its size. If multiple files are mapped, any files are individually shown, like file1, file2, ... The referenced item shows the list of referenced columns. We can see this query touches lo_orderdate, lo_quantity, lo_extendedprice and lo_discount columns.
In addition, GPU-Direct SQL: enabled (GPU-0) shows us the scan on f_lineorder uses GPU-Direct SQL mechanism.
VERBOSE option outputs more detailed information.
=# EXPLAIN VERBOSE
SELECT sum(lo_extendedprice*lo_discount) as revenue
FROM f_lineorder,date1
WHERE lo_orderdate = d_datekey
AND d_year = 1993
AND lo_discount between 1 and 3
AND lo_quantity < 25;
QUERY PLAN
--------------------------------------------------------------------------------
Aggregate (cost=14535261.08..14535261.09 rows=1 width=8)
Output: pgstrom.sum_int((pgstrom.psum(((f_lineorder.lo_extendedprice * f_lineorder.lo_discount))::bigint)))
-> Custom Scan (GpuPreAgg) on public.f_lineorder (cost=14535261.06..14535261.07 rows=1 width=32)
Output: (pgstrom.psum(((f_lineorder.lo_extendedprice * f_lineorder.lo_discount))::bigint))
GPU Projection: pgstrom.psum(((f_lineorder.lo_extendedprice * f_lineorder.lo_discount))::bigint)
GPU Scan Quals: ((f_lineorder.lo_discount >= 1) AND (f_lineorder.lo_discount <= 3) AND (f_lineorder.lo_quantity < 25)) [rows: 5999990000 -> 9999983]
GPU Join Quals [1]: (f_lineorder.lo_orderdate = date1.d_datekey) ... [nrows: 9999983 -> 1428010]
GPU Outer Hash [1]: f_lineorder.lo_orderdate
GPU Inner Hash [1]: date1.d_datekey
referenced: lo_orderdate, lo_quantity, lo_extendedprice, lo_discount
file0: /opt/nvme/f_lineorder_s999.arrow (read: 89.41GB, size: 502.92GB)
lo_orderdate: 22.35GB
lo_quantity: 22.35GB
lo_extendedprice: 22.35GB
lo_discount: 22.35GB
GPU-Direct SQL: enabled (GPU-0)
KVars-Slot: <slot=0, type='int4', expr='f_lineorder.lo_discount'>, <slot=1, type='int4', expr='f_lineorder.lo_quantity'>, <slot=2, type='int8', expr='(f_lineorder.lo_extendedprice * f_lineorder.lo_discount)'>, <slot=3, type='int4', expr='f_lineorder.lo_extendedprice'>, <slot=4, type='int4', expr='f_lineorder.lo_orderdate'>, <slot=5, type='int4', expr='date1.d_datekey'>
KVecs-Buffer: nbytes: 51200, ndims: 3, items=[kvec0=<0x0000-27ff, type='int4', expr='lo_discount'>, kvec1=<0x2800-4fff, type='int4', expr='lo_quantity'>, kvec2=<0x5000-77ff, type='int4', expr='lo_extendedprice'>, kvec3=<0x7800-9fff, type='int4', expr='lo_orderdate'>, kvec4=<0xa000-c7ff, type='int4', expr='d_datekey'>]
LoadVars OpCode: {Packed items[0]={LoadVars(depth=0): kvars=[<slot=4, type='int4' resno=6(lo_orderdate)>, <slot=1, type='int4' resno=9(lo_quantity)>, <slot=3, type='int4' resno=10(lo_extendedprice)>, <slot=0, type='int4' resno=12(lo_discount)>]}, items[1]={LoadVars(depth=1): kvars=[<slot=5, type='int4' resno=1(d_datekey)>]}}
MoveVars OpCode: {Packed items[0]={MoveVars(depth=0): items=[<slot=0, offset=0x0000-27ff, type='int4', expr='lo_discount'>, <slot=3, offset=0x5000-77ff, type='int4', expr='lo_extendedprice'>, <slot=4, offset=0x7800-9fff, type='int4', expr='lo_orderdate'>]}}, items[1]={MoveVars(depth=1): items=[<offset=0x0000-27ff, type='int4', expr='lo_discount'>, <offset=0x5000-77ff, type='int4', expr='lo_extendedprice'>]}}}
Scan Quals OpCode: {Bool::AND args=[{Func(bool)::int4ge args=[{Var(int4): slot=0, expr='lo_discount'}, {Const(int4): value='1'}]}, {Func(bool)::int4le args=[{Var(int4): slot=0, expr='lo_discount'}, {Const(int4): value='3'}]}, {Func(bool)::int4lt args=[{Var(int4): slot=1, expr='lo_quantity'}, {Const(int4): value='25'}]}]}
Join Quals OpCode: {Packed items[1]={JoinQuals: {Func(bool)::int4eq args=[{Var(int4): kvec=0x7800-a000, expr='lo_orderdate'}, {Var(int4): slot=5, expr='d_datekey'}]}}}
Join HashValue OpCode: {Packed items[1]={HashValue arg={Var(int4): kvec=0x7800-a000, expr='lo_orderdate'}}}
Partial Aggregation OpCode: {AggFuncs <psum::int[slot=2, expr='(lo_extendedprice * lo_discount)']> arg={SaveExpr: <slot=2, type='int8'> arg={Func(int8)::int8 arg={Func(int4)::int4mul args=[{Var(int4): kvec=0x5000-7800, expr='lo_extendedprice'}, {Var(int4): kvec=0x0000-2800, expr='lo_discount'}]}}}}
Partial Function BufSz: 16
-> Seq Scan on public.date1 (cost=0.00..78.95 rows=365 width=4)
Output: date1.d_datekey
Filter: (date1.d_year = 1993)
(28 rows)
The verbose output additionally displays amount of column-data to be loaded on reference of columns. The load of lo_orderdate, lo_quantity, lo_extendedprice and lo_discount columns needs to read 89.41GB in total. It is 17.8% towards the filesize (502.93GB).
Arrow_Fdw Virtual Column
Arrow_Fdw allows to map multiple Apache Arrow files with compatible schema structures to a single foreign table. For example, if `dir '/opt/arrow/mydata' is configured for foreign table option, all files under that directory will be mapped.
When you are converting the contents of a transactional database into an Apache Arrow file, we often dump them to separate files by year and month or specific categories, and its file names reflects these properties.
The example below shows an example to convert the transactional table lineorder into Arrow files by year of lo_orderdate and by category of lo_shipmode.
$ for s in RAIL AIR TRUCK SHIP FOB MAIL;
do
for y in 1993 1994 1995 1996 1997;
do
pg2arrow -d ssbm -c "SELECT * FROM lineorder_small \
WHERE lo_orderdate between ${y}0101 and ${y}1231 \
AND lo_shipmode = '${s}'" \
-o /opt/arrow/mydata/f_lineorder_${y}_${s}.arrow
done
done
$ ls /opt/arrow/mydata/
f_lineorder_1993_AIR.arrow f_lineorder_1995_RAIL.arrow
f_lineorder_1993_FOB.arrow f_lineorder_1995_SHIP.arrow
f_lineorder_1993_MAIL.arrow f_lineorder_1995_TRUCK.arrow
f_lineorder_1993_RAIL.arrow f_lineorder_1996_AIR.arrow
f_lineorder_1993_SHIP.arrow f_lineorder_1996_FOB.arrow
f_lineorder_1993_TRUCK.arrow f_lineorder_1996_MAIL.arrow
f_lineorder_1994_AIR.arrow f_lineorder_1996_RAIL.arrow
f_lineorder_1994_FOB.arrow f_lineorder_1996_SHIP.arrow
f_lineorder_1994_MAIL.arrow f_lineorder_1996_TRUCK.arrow
f_lineorder_1994_RAIL.arrow f_lineorder_1997_AIR.arrow
f_lineorder_1994_SHIP.arrow f_lineorder_1997_FOB.arrow
f_lineorder_1994_TRUCK.arrow f_lineorder_1997_MAIL.arrow
f_lineorder_1995_AIR.arrow f_lineorder_1997_RAIL.arrow
f_lineorder_1995_FOB.arrow f_lineorder_1997_SHIP.arrow
f_lineorder_1995_MAIL.arrow f_lineorder_1997_TRUCK.arrow
All these Apache Arrow files have the same schema structure and can be mapped to a single foreign table using the dir option.
Also, the Arrow file that has '1995' token in the file name only contains records with lo_orderdate in the range 19950101 to 19951231. The Arrow file that has 'RAIL' token in the file name only contains records with lo_shipmode of RAIL.
In other words, even if you define the Arrow_Fdw foreign table that maps these multiple Arrow files, when reading data from a file whose file name includes 1995, it is assumed that the value of lo_orderdate is in the range of 19950101 to 19951231. It is possible for the optimizer to utilize this knowledge.
In Arrow_Fdw, you can refer to part of the file name as a column by using the foreign table option pattern. This is called a virtual column and is configured as follows.
=# IMPORT FOREIGN SCHEMA f_lineorder
FROM SERVER arrow_fdw INTO public
OPTIONS (dir '/opt/arrow/mydata', pattern 'f_lineorder_@{year}_${shipping}.arrow');
IMPORT FOREIGN SCHEMA
=# \d f_lineorder
Foreign table "public.f_lineorder"
Column | Type | Collation | Nullable | Default | FDW options
--------------------+---------------+-----------+----------+---------+----------------------
lo_orderkey | numeric | | | |
lo_linenumber | integer | | | |
lo_custkey | numeric | | | |
lo_partkey | integer | | | |
lo_suppkey | numeric | | | |
lo_orderdate | integer | | | |
lo_orderpriority | character(15) | | | |
lo_shippriority | character(1) | | | |
lo_quantity | numeric | | | |
lo_extendedprice | numeric | | | |
lo_ordertotalprice | numeric | | | |
lo_discount | numeric | | | |
lo_revenue | numeric | | | |
lo_supplycost | numeric | | | |
lo_tax | numeric | | | |
lo_commit_date | character(8) | | | |
lo_shipmode | character(10) | | | |
year | bigint | | | | (virtual 'year')
shipping | text | | | | (virtual 'shipping')
Server: arrow_fdw
FDW options: (dir '/opt/arrow/mydata', pattern 'f_lineorder_@{year}_${shipping}.arrow')
This foreign table option pattern contains two wildcards.
@{year} matches a numeric string larger than or equal to 0 characters, and ${shipping} matches a string larger than or equal to 0 characters.
The patterns that match this part of the file name can be referenced in the part specified by the virtual column option.
In this case, IMPORT FOREIGN SCHEMA automatically adds column definitions, in addition to the fields contained in the Arrow file itself, as well as the virtual column year (a bigint column) that references the wildcard @{year}, and the virtual column shipping that references the wildcard ${shipping}.
=# SELECT lo_orderkey, lo_orderdate, lo_shipmode, year, shipping
FROM f_lineorder
WHERE year = 1995 AND shipping = 'AIR'
LIMIT 10;
lo_orderkey | lo_orderdate | lo_shipmode | year | shipping
-------------+--------------+-------------+------+----------
637892 | 19950512 | AIR | 1995 | AIR
638243 | 19950930 | AIR | 1995 | AIR
638273 | 19951214 | AIR | 1995 | AIR
637443 | 19950805 | AIR | 1995 | AIR
637444 | 19950803 | AIR | 1995 | AIR
637510 | 19950831 | AIR | 1995 | AIR
637504 | 19950726 | AIR | 1995 | AIR
637863 | 19950802 | AIR | 1995 | AIR
637892 | 19950512 | AIR | 1995 | AIR
637987 | 19950211 | AIR | 1995 | AIR
(10 rows)
In other words, you can know what values the virtual columns have before reading the Arrow file mapped by the Arrow_Fdw foreign table. By this feature, if it is obvious that there is no match at all from the search conditions before reading a certain Arrow file, it is possible to skip reading the file itself.
See the query and its EXPLAIN ANALYZE output below.
This aggregation query reads the f_lineorder foreign table, filters it by some conditions, and then aggregates the total value of lo_extendedprice * lo_discount.
At that time, the conditional clause WHERE year = 1994 is added. This is effectively the same as WHERE lo_orderdate BETWEEN 19940101 AND 19942131, but since year is a virtual column, you can determine whether a matching row exists before reading the Arrow files.
In fact, looking at the Stats-Hint: line, 12 Record-Batches were loaded due to the condition (year = 1994), but 48 Record-Batches were skipped. This is a simple but extremely effective means of reducing I/O load.
=# EXPLAIN ANALYZE
SELECT sum(lo_extendedprice*lo_discount) as revenue
FROM f_lineorder
WHERE year = 1994
AND lo_discount between 1 and 3
AND lo_quantity < 25;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------
Aggregate (cost=421987.07..421987.08 rows=1 width=32) (actual time=82.914..82.915 rows=1 loops=1)
-> Custom Scan (GpuPreAgg) on f_lineorder (cost=421987.05..421987.06 rows=1 width=32) \
(actual time=82.901..82.903 rows=2 loops=1)
GPU Projection: pgstrom.psum(((lo_extendedprice * lo_discount))::double precision)
GPU Scan Quals: ((year = 1994) AND (lo_discount <= '3'::numeric) AND \
(lo_quantity < '25'::numeric) AND \
(lo_discount >= '1'::numeric)) [plan: 65062080 -> 542, exec: 13001908 -> 1701726]
referenced: lo_quantity, lo_extendedprice, lo_discount, year
Stats-Hint: (year = 1994) [loaded: 12, skipped: 48]
file0: /opt/arrow/mydata/f_lineorder_1996_MAIL.arrow (read: 99.53MB, size: 427.16MB)
file1: /opt/arrow/mydata/f_lineorder_1996_SHIP.arrow (read: 99.52MB, size: 427.13MB)
file2: /opt/arrow/mydata/f_lineorder_1994_FOB.arrow (read: 99.18MB, size: 425.67MB)
: : : :
file27: /opt/arrow/mydata/f_lineorder_1997_MAIL.arrow (read: 99.23MB, size: 425.87MB)
file28: /opt/arrow/mydata/f_lineorder_1995_MAIL.arrow (read: 99.16MB, size: 425.58MB)
file29: /opt/arrow/mydata/f_lineorder_1993_TRUCK.arrow (read: 99.24MB, size: 425.91MB)
GPU-Direct SQL: enabled (N=2,GPU0,1; direct=76195, ntuples=13001908)
Planning Time: 2.402 ms
Execution Time: 83.857 ms
(39 rows)
How to make Arrow files
This section introduces the way to transform dataset already stored in PostgreSQL database system into Apache Arrow file.
Using PyArrow+Pandas
A pair of PyArrow module, developed by Arrow developers community, and Pandas data frame can dump PostgreSQL database into an Arrow file.
The example below reads all the data in table t0, then write out them into /tmp/t0.arrow.
import pyarrow as pa
import pandas as pd
X = pd.read_sql(sql="SELECT * FROM t0", con="postgresql://localhost/postgres")
Y = pa.Table.from_pandas(X)
f = pa.RecordBatchFileWriter('/tmp/t0.arrow', Y.schema)
f.write_table(Y,1000000) # RecordBatch for each million rows
f.close()
Please note that the above operation once keeps query result of the SQL on memory, so should pay attention on memory consumption if you want to transfer massive rows at once.
Using Pg2Arrow
On the other hand, pg2arrow command, developed by PG-Strom Development Team, enables us to write out query result into Arrow file. This tool is designed to write out massive amount of data into storage device like NVME-SSD. It fetch query results from PostgreSQL database system, and write out Record Batches of Arrow format for each data size specified by the -s|--segment-size option. Thus, its memory consumption is relatively reasonable.
pg2arrow command is distributed with PG-Strom. It shall be installed on the bin directory of PostgreSQL related utilities.
$ pg2arrow --help
Usage:
pg2arrow [OPTION] [database] [username]
General options:
-d, --dbname=DBNAME Database name to connect to
-c, --command=COMMAND SQL command to run
-t, --table=TABLENAME Equivalent to '-c SELECT * FROM TABLENAME'
(-c and -t are exclusive, either of them must be given)
--inner-join=SUB_COMMAND
--outer-join=SUB_COMMAND
-o, --output=FILENAME result file in Apache Arrow format
--append=FILENAME result Apache Arrow file to be appended
(--output and --append are exclusive. If neither of them
are given, it creates a temporary file.)
-S, --stat[=COLUMNS] embeds min/max statistics for each record batch
COLUMNS is a comma-separated list of the target
columns if partially enabled.
Arrow format options:
-s, --segment-size=SIZE size of record batch for each
Connection options:
-h, --host=HOSTNAME database server host
-p, --port=PORT database server port
-u, --user=USERNAME database user name
-w, --no-password never prompt for password
-W, --password force password prompt
Other options:
--dump=FILENAME dump information of arrow file
--progress shows progress of the job
--set=NAME:VALUE config option to set before SQL execution
--help shows this message
Report bugs to <pgstrom@heterodbcom>.
The -h or -U option specifies the connection parameters of PostgreSQL, like psql or pg_dump. The simplest usage of this command is running a SQL command specified by -c|--command option on PostgreSQL server, then write out results into the file specified by -o|--output option in Arrow format.
--append option is available, instead of -o|--output option. It means appending data to existing Apache Arrow file. In this case, the target Apache Arrow file must have fully identical schema definition towards the specified SQL command.
The example below reads all the data in table t0, then write out them into the file /tmp/t0.arrow.
$ pg2arrow -U kaigai -d postgres -c "SELECT * FROM t0" -o /tmp/t0.arrow
Although it is an option for developers, --dump <filename> prints schema definition and record-batch location and size of Arrow file in human readable form.
--progress option enables to show progress of the task. It is useful when a huge table is transformed to Apache Arrow format.
Advanced Usage
SSDtoGPU Direct SQL
In case when all the Arrow files mapped on the Arrow_Fdw foreign table satisfies the terms below, PG-Strom enables SSD-to-GPU Direct SQL to load columnar data.
- Arrow files are on NVME-SSD volume.
- NVME-SSD volume is managed by Ext4 filesystem.
- Total size of Arrow files exceeds the
pg_strom.nvme_strom_thresholdconfiguration.
Partition configuration
Arrow_Fdw foreign tables can be used as a part of partition leafs. Usual PostgreSQL tables can be mixtured with Arrow_Fdw foreign tables. So, pay attention Arrow_Fdw foreign table does not support any writer operations. And, make boundary condition of the partition consistent to the contents of the mapped Arrow file. It is a responsibility of the database administrators.
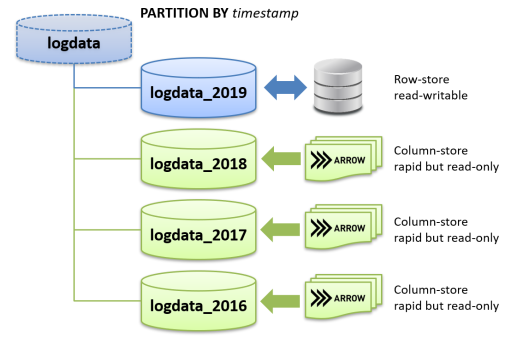
A typical usage scenario is processing of long-standing accumulated log-data.
Unlike transactional data, log-data is mostly write-once and will never be updated / deleted. Thus, by migration of the log-data after a lapse of certain period into Arrow_Fdw foreign table that is read-only but rapid processing, we can accelerate summarizing and analytics workloads. In addition, log-data likely have timestamp, so it is quite easy design to add partition leafs periodically, like monthly, weekly or others.
The example below defines a partitioned table that mixes a normal PostgreSQL table and Arrow_Fdw foreign tables.
The normal PostgreSQL table, is read-writable, is specified as default partition, so DBA can migrate only past log-data into Arrow_Fdw foreign table under the database system operations.
CREATE TABLE lineorder (
lo_orderkey numeric,
lo_linenumber integer,
lo_custkey numeric,
lo_partkey integer,
lo_suppkey numeric,
lo_orderdate integer,
lo_orderpriority character(15),
lo_shippriority character(1),
lo_quantity numeric,
lo_extendedprice numeric,
lo_ordertotalprice numeric,
lo_discount numeric,
lo_revenue numeric,
lo_supplycost numeric,
lo_tax numeric,
lo_commit_date character(8),
lo_shipmode character(10)
) PARTITION BY RANGE (lo_orderdate);
CREATE TABLE lineorder__now PARTITION OF lineorder default;
CREATE FOREIGN TABLE lineorder__1993 PARTITION OF lineorder
FOR VALUES FROM (19930101) TO (19940101)
SERVER arrow_fdw OPTIONS (file '/opt/tmp/lineorder_1993.arrow');
CREATE FOREIGN TABLE lineorder__1994 PARTITION OF lineorder
FOR VALUES FROM (19940101) TO (19950101)
SERVER arrow_fdw OPTIONS (file '/opt/tmp/lineorder_1994.arrow');
CREATE FOREIGN TABLE lineorder__1995 PARTITION OF lineorder
FOR VALUES FROM (19950101) TO (19960101)
SERVER arrow_fdw OPTIONS (file '/opt/tmp/lineorder_1995.arrow');
CREATE FOREIGN TABLE lineorder__1996 PARTITION OF lineorder
FOR VALUES FROM (19960101) TO (19970101)
SERVER arrow_fdw OPTIONS (file '/opt/tmp/lineorder_1996.arrow');
Below is the query execution plan towards the table. By the query condition lo_orderdate between 19950701 and 19960630 that touches boundary condition of the partition, the partition leaf lineorder__1993 and lineorder__1994 are pruned, so it makes a query execution plan to read other (foreign) tables only.
=# EXPLAIN
SELECT sum(lo_extendedprice*lo_discount) as revenue
FROM lineorder,date1
WHERE lo_orderdate = d_datekey
AND lo_orderdate between 19950701 and 19960630
AND lo_discount between 1 and 3
ABD lo_quantity < 25;
QUERY PLAN
--------------------------------------------------------------------------------
Aggregate (cost=172088.90..172088.91 rows=1 width=32)
-> Hash Join (cost=10548.86..172088.51 rows=77 width=64)
Hash Cond: (lineorder__1995.lo_orderdate = date1.d_datekey)
-> Append (cost=10444.35..171983.80 rows=77 width=67)
-> Custom Scan (GpuScan) on lineorder__1995 (cost=10444.35..33671.87 rows=38 width=68)
GPU Filter: ((lo_orderdate >= 19950701) AND (lo_orderdate <= 19960630) AND
(lo_discount >= '1'::numeric) AND (lo_discount <= '3'::numeric) AND
(lo_quantity < '25'::numeric))
referenced: lo_orderdate, lo_quantity, lo_extendedprice, lo_discount
files0: /opt/tmp/lineorder_1995.arrow (size: 892.57MB)
-> Custom Scan (GpuScan) on lineorder__1996 (cost=10444.62..33849.21 rows=38 width=68)
GPU Filter: ((lo_orderdate >= 19950701) AND (lo_orderdate <= 19960630) AND
(lo_discount >= '1'::numeric) AND (lo_discount <= '3'::numeric) AND
(lo_quantity < '25'::numeric))
referenced: lo_orderdate, lo_quantity, lo_extendedprice, lo_discount
files0: /opt/tmp/lineorder_1996.arrow (size: 897.87MB)
-> Custom Scan (GpuScan) on lineorder__now (cost=11561.33..104462.33 rows=1 width=18)
GPU Filter: ((lo_orderdate >= 19950701) AND (lo_orderdate <= 19960630) AND
(lo_discount >= '1'::numeric) AND (lo_discount <= '3'::numeric) AND
(lo_quantity < '25'::numeric))
-> Hash (cost=72.56..72.56 rows=2556 width=4)
-> Seq Scan on date1 (cost=0.00..72.56 rows=2556 width=4)
(16 rows)
The operation below extracts the data in 1997 from lineorder__now table, then move to a new Arrow_Fdw foreign table.
$ pg2arrow -d sample -o /opt/tmp/lineorder_1997.arrow \
-c "SELECT * FROM lineorder WHERE lo_orderdate between 19970101 and 19971231"
pg2arrow command extracts the data in 1997 from the lineorder table into a new Arrow file.
BEGIN;
--
-- remove rows in 1997 from the read-writable table
--
DELETE FROM lineorder WHERE lo_orderdate BETWEEN 19970101 AND 19971231;
--
-- define a new partition leaf which maps log-data in 1997
--
CREATE FOREIGN TABLE lineorder__1997 PARTITION OF lineorder
FOR VALUES FROM (19970101) TO (19980101)
SERVER arrow_fdw OPTIONS (file '/opt/tmp/lineorder_1997.arrow');
COMMIT;
A series of operations above delete the data in 1997 from lineorder__new that is a PostgreSQL table, then maps an Arrow file (/opt/tmp/lineorder_1997.arrow) which contains an identical contents as a foreign table lineorder__1997.
-
For correctness, block size is configurable on build from 4KB to 32KB. ↩