GPU Cache
Overview
GPU has a device memory that is independent of the RAM in the host system, and in order to calculate on the GPU, data must be transferred from the host system or storage device to the GPU device memory once through the PCI-E bus. The same is true when PG-Strom processes SQL queries on the GPU. Internally, the records read from the PostgreSQL table are transferred to the GPU, and then various SQL operations are executed on the GPU. However, these processes take time to read the tables and transfer the data. (In many cases, much longer than the processing on the GPU!)
GPU Cache is a function that reserves an area on the GPU device memory in advance and keeps a copy of the PostgreSQL table there. This can be used to execute search/analysis SQL in real time for data that is relatively small(~10GB) and is frequently updated. The log-based synchronization mechanism described below allows GPU Cache to be kept up-to-date without interfering with highly parallel and transactional workloads. Nevertheless, you can process search/analytical SQL workloads on data already loaded on GPU Cache without reading the records from the table again or transferring the data over the PCI-E bus.
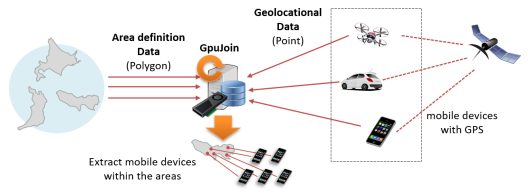
A typical use case of GPU Cache is to join location data, such as the current position of a mobile device like a car or a cell phone, collected in real time with other data using GPU-PostGIS. The workload of updating location information sent out by many devices is extremely heavy. However, it also needs to be applied on the GPU side without delay in order to perform search/analysis queries based on the latest location information. Although the size is limited, GPU Cache is one option to achieve both high frequency updates and high-performance search/analysis query execution.
Architecture
GPU Caches needs to satisfy two requirements: highly parallel update-based workloads and search/analytical queries on constantly up-to-date data. In many systems, the CPU and GPU are connected via the PCI-E bus, and there is a reasonable delay in their communication. Therefore, synchronizing GPU Cache every time a row is updated in the target table will significantly degrade the transaction performance. Using GPU Cache allocates a "REDO Log Buffer" on the shared memory on the host side in addition to the area on the memory of the GPU. When a SQL command (INSERT, UPDATE, DELETE) is executed to update a table, the updated contents are copied to the REDO Log Buffer by the AFTER ROW trigger. Since this process can be completed by CPU and RAM alone without any GPU call, it has little impact on transaction performance.
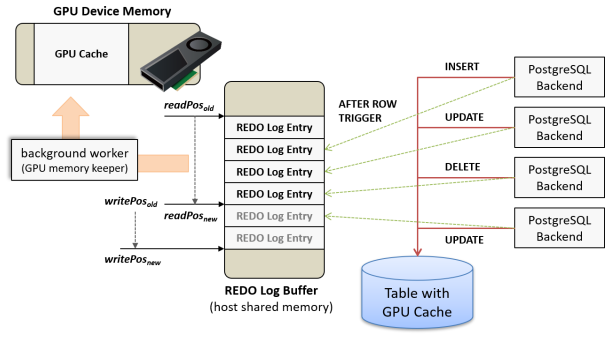
When a certain amount of unapplied REDO Log Entries accumulate in the REDO Log Buffer, or a certain amount of time has passed since the last write, it is loaded by a background worker process (GPU memory keeper) and applied to GPU Cache. At this time, REDO Log Entries are transferred to the GPU in batches and processed in parallel by thousands of processor cores on the GPU, so delays caused by this process are rarely a problem.
Search/analysis queries against the target table in GPU Cache do not load the table data, but use the data mapped from GPU Cache pre-allocated on the GPU device memory. If there are any unapplied REDO Logs at the start of the search/analysis query, they will all be applied to GPU Cache. This means that the results of a search/analysis query scanning the target GPU Cache will return the same results as if it were referring to the table directly, and the query will always be consistent.
Configuration
To enable GPU Cache, configure a trigger that executes pgstrom.gpucache_sync_trigger() function
on AFTER INSERT OR UPDATE OR DELETE for each row.
If GPU Cache is used on the replication slave, the invocation mode of this trigger must be ALWAYS.
Below is an example to configure GPU Cache on the dpoints table.
=# create trigger row_sync after insert or update or delete on dpoints_even for row
execute function pgstrom.gpucache_sync_trigger();
=# alter table dpoints_even enable always trigger row_sync;
GPU Cache Customize
You can customize GPU Cache by specifying an optional string in the form of KEY=VALUE as an argument to GPU Cache line trigger. Please note that where you should specify is not to the syntax trigger. The following SQL statement is an example of creating a GPU Cache whose maximum row count is 2.5 million rows and the size of the REDO Log Buffer is 100MB.
=# create trigger row_sync after insert or update or delete on dpoints_even for row
execute function pgstrom.gpucache_sync_trigger('max_num_rows=2500000,redo_buffer_size=100m');
The options that can be given to the argument of the line trigger are shown below.
gpu_device_id=GPU_ID(default: 0)- Specify the target GPU device ID to allocate GPU Cache.
max_num_rows=NROWS(default: 10485760)- Specify the number of rows that can be allocated on GPU Cache.
- Just as with PostgreSQL tables, GPU Cache needs to retain updated rows prior to commit for visibility control, so
max_num_rowsshould be specified with some margin. Note that the old version of the updated/deleted row will be released after the transaction is committed. redo_buffer_size=SIZE(default: 160m)- Specify the size of REDO Log Buffer. You can use k, m and g as the unit.
gpu_sync_interval=SECONDS(default: 5)- If the specified time has passed since the last write to the REDO Log Buffer, REDO Log will be applied to the GPU, regardless of the number of rows updated.
gpu_sync_threshold=SIZE(default: 25% ofredo_buffer_size)- When the unapplied REDO Log in the REDO Log Buffer reaches SIZE bytes, it is applied to the GPU side.
- You can use k, m and g as the unit.
GPU Cache Options
Below are GPU Cache related PostgreSQL configuration parameters.
pg_strom.enable_gpucache(default: on)- This option controls whether search/analytical queries will use GPU Cache or not.
- If this value is off, the data will be read from the table each time, ignoring GPU Cache even if it is available.
- Note that this setting has no effect on REDO Log Buffer appending by triggers.
pg_strom.gpucache_auto_preload(default: NULL)- When PostgreSQL is started/restarted, GPU Cache for the table specified by this parameter will be built in advance.
- The value should be in the format:
DATABASE_NAME.SCHEMA_NAME.TABLE_NAME. To specify multiple tables, separate them by commas. - If GPU Cache is not built, the PostgreSQL backend process that first attempts to access GPU Cache will scan the entire target table and transfer it to the GPU. This process usually takes a considerable amount of time. However, by specifying the tables that should be loaded in this option, you can avoid waiting too long the first time you run a search/analysis query.
- If this parameter is set to '*', it will attempt to load the contents of all tables with GPU Cache into the GPU in order. At this time, the background worker will access all the databases in order, and will return exit code 1 to prompt the postmaster to restart.
- The server startup log will show that the "GPUCache Startup Preloader" exited with exit code 1 as follows, but this is not abnormal.
LOG: database system is ready to accept connections
LOG: background worker "GPUCache Startup Preloader" (PID 856418) exited with exit code 1
LOG: background worker "GPUCache Startup Preloader" (PID 856427) exited with exit code 1
LOG: create GpuCacheSharedState dpoints:164c95f71
LOG: gpucache: AllocMemory dpoints:164c95f71 (main_sz=772505600, extra_sz=0)
LOG: gpucache: auto preload 'public.dpoints' (DB: postgres)
LOG: create GpuCacheSharedState mytest:1773a589b
LOG: gpucache: auto preload 'public.mytest' (DB: postgres)
LOG: gpucache: AllocMemory mytest:1773a589b (main_sz=675028992, extra_sz=0)
Operations
Confirm GPU Cache usage
GPU Cache is referred to transparently. The user does not need to be aware of the presence or absence of GPU Cache, and PG-Strom will automatically determine and switch the process.
The following is the query plan for a query that refers to the table "dpoints" which has GPU Cache set. The 3rd row from the bottom, in the "GPU Cache" field, shows the basic information about GPU Cache of this table. We can see that the query is executed with referring to GPU Cache and not the "dpoints" table.
Note that the meaning of each item is as follows: max_num_rows indicates the maximum number of rows that GPU Cache can hold; main indicates the size of the area in GPU Cache for fixed-length fields; extra indicates the size of the area for variable-length data.
=# explain
select pref, city, count(*)
from giscity g, dpoints d
where pref = 'Tokyo'
and st_contains(g.geom,st_makepoint(d.x, d.y))
group by pref, city;
QUERY PLAN
--------------------------------------------------------------------------------------------------------
HashAggregate (cost=5638809.75..5638859.99 rows=5024 width=29)
Group Key: g.pref, g.city
-> Custom Scan (GpuPreAgg) (cost=5638696.71..5638759.51 rows=5024 width=29)
Reduction: Local
Combined GpuJoin: enabled
GPU Preference: GPU0 (NVIDIA Tesla V100-PCIE-16GB)
-> Custom Scan (GpuJoin) on dpoints d (cost=631923.57..5606933.23 rows=50821573 width=21)
Outer Scan: dpoints d (cost=0.00..141628.18 rows=7999618 width=16)
Depth 1: GpuGiSTJoin(nrows 7999618...50821573)
HeapSize: 3251.36KB
IndexFilter: (g.geom ~ st_makepoint(d.x, d.y)) on giscity_geom_idx
JoinQuals: st_contains(g.geom, st_makepoint(d.x, d.y))
GPU Preference: GPU0 (NVIDIA Tesla V100-PCIE-16GB)
GPU Cache: NVIDIA Tesla V100-PCIE-16GB [max_num_rows: 12000000, main: 772.51M, extra: 0]
-> Seq Scan on giscity g (cost=0.00..8929.24 rows=6353 width=1883)
Filter: ((pref)::text = 'Tokyo'::text)
(16 rows)
Check status of GPU Cache
Use the pgstrom.gpucache_info view to check the current state of GPU Cache.
=# select * from pgstrom.gpucache_info ;
database_oid | database_name | table_oid | table_name | signature | refcnt | corrupted | gpu_main_sz | gpu_extra_sz | redo_write_ts | redo_write_nitems | redo_write_pos | redo_read_nitems | redo_read_pos | redo_sync_pos | config_options
--------------+---------------+-----------+------------+------------+--------+-----------+-------------+--------------+----------------------------+-------------------+----------------+------------------+---------------+---------------+------------------------------------------------------------------------------------------------------------------------
12728 | postgres | 25244 | mytest | 6295279771 | 3 | f | 675028992 | 0 | 2021-05-14 03:00:18.623503 | 500000 | 36000000 | 500000 | 36000000 | 36000000 | gpu_device_id=0,max_num_rows=10485760,redo_buffer_size=167772160,gpu_sync_interval=5000000,gpu_sync_threshold=41943040
12728 | postgres | 25262 | dpoints | 5985886065 | 3 | f | 772505600 | 0 | 2021-05-14 03:00:18.524627 | 8000000 | 576000192 | 8000000 | 576000192 | 576000192 | gpu_device_id=0,max_num_rows=12000000,redo_buffer_size=167772160,gpu_sync_interval=5000000,gpu_sync_threshold=41943040
(2 rows)
Note that pgstrom.gpucache_info will only show the status of GPU Caches that have been initially loaded and have space allocated on the GPU device memory at that time. In other words, if the trigger function is set but not yet initially loaded (no one has accessed it yet), the potentially allocated GPU Cache will not be shown yet.
The meaning of each field is as follows:
database_oid- The OID of the database to which the table with GPU Cache enabled exists.
database_name- The name of the database to which the table with GPU Cache enabled exists.
table_oid- The OID of the table with GPU Cache enabled. Note that the database this table exists in is not necessarily the database you are connected to.
table_name- The name of the table with GPU Cache enabled. Note that the database this table exists in is not necessarily the database you are connected to.
signature- A hash value indicating the uniqueness of GPU Cache. This value may change, for example, before and after executing
ALTER TABLE.
- A hash value indicating the uniqueness of GPU Cache. This value may change, for example, before and after executing
refcnt- Reference counter of the GPU Cache. It does not always reflect the latest value.
corrupted- Shows whether the GPU Cache is corrupted.
gpu_main_sz- The size of the area reserved in GPU Cache for fixed-length data.
gpu_extra_sz- The size of the area reserved in GPU Cache for variable-length data.
redo_write_ts- The time when the REDO Log Buffer was last updated.
redo_write_nitems- The total number of REDO Logs in the REDO Log Buffer.
redo_write_pos- The total size (in bytes) of the REDO Logs in the REDO Log Buffer.
redo_read_nitems- The total number of REDO Logs read from the REDO Log Buffer and applied to the GPU.
redo_read_pos- The total size (in bytes) of REDO Logs read from the REDO Log Buffer and applied to the GPU.
redo_sync_pos- The position of the REDO Log which is scheduled to be applied to GPU Cache by the background worker on the REDO Log Buffer.
- This is used internally to avoid a situation where many sessions generate asynchronous requests at the same time when the remaining REDO Log Buffer is running out.
config_options- The optional string to customize GPU Cache.
GPU Cache corruption and recovery
If and when REDO logs could not be applied on the GPU cache by some reasons, like insertion of more rows than the max_num_rows configuration, or too much consumption of variable-length data buffer, GPU cache moves to the "corrupted" state.
Once GPU cache gets corrupted, search/analysis SQL does not reference the GPU cache, and table updates stops writing REDO log. (If GPU cache gets corrupted after beginning of a search/analysis SQL unfortunately, this query may raise an error.)
The pgstrom.gpucache_recovery(regclass) function recovers the GPU cache from the corrupted state.
If you run this function after removal of the cause where REDO logs could not be applied, it runs initial-loading of the GPU cache again, then tries to recover the GPU cache.
For example, if GPU cache gets corrupted because you tried to insert more rows than the max_num_rows, you reconfigure the trigger with expanded max_num_rows configuration or you delete a part of rows from the table, then runs pgstrom.gpucache_recovery() function.